引用自生信技能树马拉松课程小洁老师授课内容:R语言基础01
生成变量
c(1,5,3)
1:3
rep("x",times=3) #有重复的用rep()
seq(from=3,to=21,by=3)#有规律的序列用seq()
rnorm(n=3)#随机数用rnorm()
#通过组合,产生更为复杂的向量:
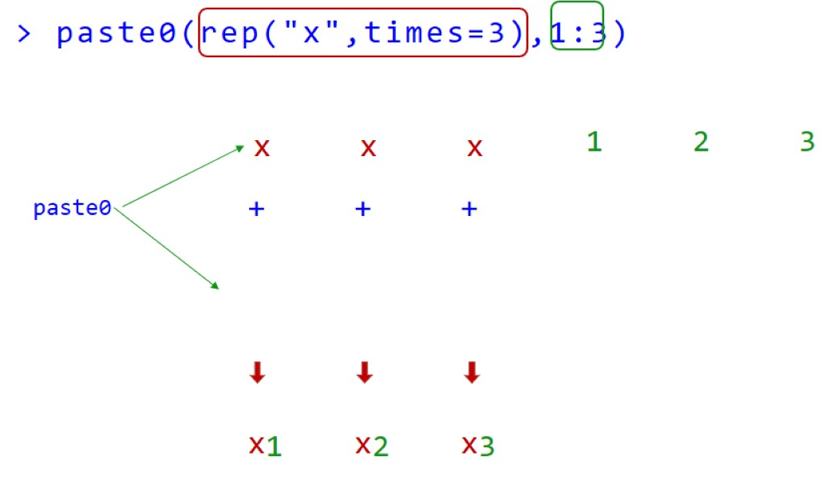
paste0(rep("x",times=3),1:3)
## [1] "x1" "x2" "x3"
paste0(rep('student'),seq(2,15,2))
## [1] "student2" "student4" "student6" "student8"
## [5] "student10" "student12" "student14"
比较运算与逻辑运算


循环补齐
a = c(1,2,3,4,1)
b = c(1,2)
#循环补齐一般包括三种情况:
#1.算数计算
a+b
## [1] 2 4 4 6 2
#2.逻辑比较:等于不等于大于小于百分百in
a==b
## [1] TRUE TRUE FALSE FALSE TRUE
a>b
## [1] FALSE FALSE TRUE TRUE FALSE
a %in% b
## [1] TRUE TRUE FALSE FALSE TRUE
#3.paste&paste0
paste0(rep("x"),1:3) #sep=","
## [1] "x1" "x2" "x3"交集、并集、差集、%in%与==的区别
x = c(1,3,5,1)
y = c(3,2,5,6)
#交集、并集、差集
intersect(x,y)#交集
union(x,y)#并集
setdiff(x,y) #x里有y里没有
setdiff(y,x)
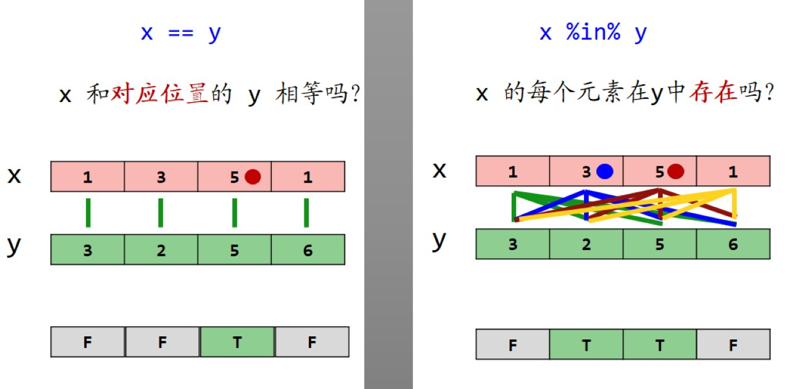
#%in%与==的区别
> x == y #将x里的元素与y里的元素**一一对应**的比较,确认是否相等
## [1] FALSE FALSE TRUE FALSE
> x %in% y #将x里的元素与y里的**每一个元素**比较,确认是否相等
## [1] FALSE TRUE TRUE TRUE
向量筛选
a = c(1,2,3,4,1)
#按照逻辑值:中括号内为与x等长且一一对应的逻辑值向量
a[!duplicated(a)]
## [1] 1 2 3 4
#按照位置:中括号里是x的下标组成的向量
a[3]
## [1] 3长度与重复
x = c("1","2","3","4","2")
length(x) #长度:计数x
## [1] 5
unique(x) #去重复:去除x里的重复值(每一个数据第一次出现为T,第二次出现为F,结果为保留重复值的第一次出现)
## [1] "1" "2" "3" "4"
duplicated(x) #对应元素是否重复,返回逻辑值,重复为T
## [1] FALSE FALSE FALSE FALSE TRUE
!duplicated(x)#对应元素是否重复,返回逻辑值,不重复为T
## [1] TRUE TRUE TRUE TRUE FALSE
table(x) #重复值统计,每一个值出现的次数
## x
## 1 2 3 4
## 1 2 1 1
table(duplicated(x))#统计多少个值为唯一,多少个值重复
## FALSE TRUE
## 4 1一些tips
- 按tab可以自动填充函数、路径等
- NA:逻辑值,存在,但不知道; null:不存在
- 一个向量只能有一种数据类型,可以有重复值
- R语言的修改都需要赋值
- 熟练运用proj
- 不是没报错就没问题,需检查目的是否达到
- 脚本打开全是乱码的解决方案:
脚本打开全是乱码的解决方案
引用自生信技能树马拉松课程小洁老师授课内容:R语言基础01
正文完