一、TDBank接入hive数据的痛点和挑战
数据接入到Hive是TDW数据接入中应用最广泛的场景,整体的数据流向路径如下所示:
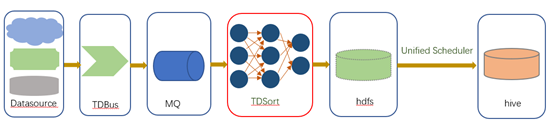
图1 数据接入到TDW Hive的流向路径
数据从源侧发送,经过TDBus后存入MQ,然后由TDSort消费并根据业务规则进行分拣处理后存入中转的hdfs目录,再由配置的统一调度任务定时将数据以分区为单位写入hive仓库。可以看出,整个系统数据流经的环节较多,对运维和用户具有如下的痛点:
- 难以保证实时入库。数据多次流转、统一调度本身调度的延迟、hdfs性能的抖动、gaia资源的竞争(统一调度会通过hive生成gaia应用执行实际入库逻辑)等都会导致入库延迟。
- 接入质量无法衡量。由于缺少入库数据的对账环节,导致往往难以在第一时间感知到数据接入质量的好坏。
- 接入和运维成本高。整个过程需要额外准备hdfs存储资源、统一调度资源、hive资源、gaia计算资源,需维护这些资源和服务的可用性。这里面仅仅是统一调度的入库任务就占其总任务量的一半左右,给统一调度也带来了巨大的计算量。
整个过程需要额外的物力和人力投入,且还无法保证入库的及时性(不考虑数据迟到话入库延迟一般在30分钟到几小时之间)。
除此之外,大数据接入还有如下的挑战:
- 高流量和易运维性
目前tdbank接入的hive表总数为153978,日均的接入量为30万亿左右,其中最大的业务日均接入量达8万亿+。一方面流量巨大使得接入中断或重启的成本非常高,一方面需接入的hive表和业务规则众多,而我们需要根据业务规则把数据按照相应的格式落地到对应的hive。而这里的接入数据和业务规则往往会动态变化,故我们需要灵活高效的适应业务规则的变动。
- 接入延迟和数据碎片
接入延迟和数据碎片是一对矛盾体。追求低接入延迟会导致产生数据碎片,不利于HDFS的存储,并降低数据查询的效率。而高接入延迟在某些场景下无法被用户接受,在实际中需要权衡。
- 异常处理和数据一致性
流式数据处理过程中随时可能因为机器、磁盘、人为、软件等故障原因中断或重启,这种情况下必然有一部分数据是on the fly的,从而导致了不一致性,在大数据流量场景下会更加明显。Flink作为流式数据处理领域最流行的框架为我们提供了分布式系统流式数据处理时具有exactly_once语义的checkpoint机制,以帮助解决异常恢复问题,但应用仍然需要自己处理source和sink的状态保存和恢复,其中sink侧的处理尤其具有挑战性。
- 指标统计
从业务和运维角度,需要按表分区的维度统计指标数据。分布式系统中指标统计会面临两个问题:一是如何对指标按所需维度做汇聚;二是异常恢复时如何对指标进行回滚。
- 数据(负载)倾斜
TDSort运行在gaia上,gaia目前只支持对CPU和内存进行管控,而流式数据处理中IO资源,尤其是网络IO也是一种宝贵的资源。在大数据流量场景下极易发生因节点流量不均匀而导致的数据倾斜。
- 故障转移
大流量下,流式数据处理应用启停的代价相对较高,而机器、磁盘等经常会因为一些原因发生故障,这时需要有便利的手段使得运维人员可以进行剔除gaia节点、切换gaia集群等操作。
- Sink(HDFS)性能抖动
HDFS性能抖动或故障除了导致数据无法写入、吞吐降低外,还会导致TDSort做checkpoint时因超时而失败。
二、接入实时性优化和功能增强
TDBus可以帮助收敛MQ的producer连接数并提供一个业务维度指标统计的切入点,MQ是数据暂存并可削峰平谷、解耦数据发送和数据处理,TDSort作为类似ETL或者data pipeline的角色承载了主要的数据接入逻辑,从业务角度审视都有其存在的必要性。入库任务主要承担如下功能:
- 根据调度配置定期去中转的hdfs目录上检查某个分区的数据是否已准备就绪;
- 准备就绪后创建hive外表,然后通过执行sql将数据从中转目录插入到实际的hive分区目录,这个过程是统一调度提交sql到hive server,hive server再在gaia上提交并运行任务完成的,中间涉及到的数据格式的转换也都是gaia上的任务来完成的。
基于以上分析,我们做了如下优化:
- 去除了统一调度任务入库的逻辑,业务数据由TDSort直接写入hive库。为了做到直接入库,TDSort除了需要获取到hive库表、分区等相关信息外,还需要支持将源数据转换为所需要的hive文件格式、压缩类型等。
- 提供了高效的分区入库状态查询服务TDLedger
- 增加了端到端对账的支持,同样由TDLedger承载。
- 对checkpoint的全面支持。
- 通过oceanus平台启停TDSort应用。Oceanus为我们提供了方便的任务启停、checkpoint保存、历史checkpoint点管理和恢复、资源管理和审批等功能,让我们可以聚焦于业务本身。
优化后的数据流向图如下所示:
图2 优化后的hive数据接入流向
除了数据流向本身的优化外,图中同时新增了入口指标流和出口指标流的统计计算,并在TDLedger侧进行对账,这对用户和运维侧也是非常重要的功能。
三、接入实时性优化效果
以日均接入6000亿、gzip压缩、文本格式接入的业务为例,下面为优化前后的对比:
- 入库延迟可以满足TP99<15min
图3 优化后hive入库延迟时间分布
- 有效降低了成本和资源的投入,包括hdfs存储资源、统一调度资源、hive资源、gaia计算资源等。
- 很自然地解决了数据迟到问题,不论迟到多久的数据都可以安全入库,同时也允许其他渠道来源的数据写入。
- 降低了系统复杂度,入库不再需要统一调度的支持,不再依赖运维侧的一些脚本。
- 通过oceanus统一管理了历史checkpoint、资源、权限、任务启停等,并将TDSort运行在gaia上,从而更便于运维和维护。
四、其他接入挑战的解决实践
1. 高流量和易运维性
- 对topic内的数据抽象了tid的概念,每个tid和一个hive表关联,每条数据归属于一个tid,这样就可以在一个topic内接入多个hive表的数据。
- 基于zookeeper做了配置服务,这样可以动态的下发配置和感知变动,并动态的接入新的topic。
- 接入服务TDSort基于流式数据处理领域最流行的flink开发,采用如下的拓扑结构:
图4 TDSort拓扑结构
2. 接入延迟和数据碎片
- 定义单个文件最大大小和最大数据延迟两个维度,业务根据需要进行配置。
- 对接入延迟容忍度较低的业务,通过小文件压缩任务定期对小文件进行合并。
3. 异常处理和数据一致性
- Source侧:Checkpoint时保存MQ的offset信息,这样异常时就可以从前一个成功的checkpoint进行恢复。
- Sink侧:对落地的HDFS文件名进行特意设计,这样我们从checkpoint恢复进行rollback时才能知道哪些文件是可以被安全删除的。这里不能根据文件的修改时间戳进行判断,因为每个gaia节点的时钟并不一定是完全一致的,而HDFS的性能也会有抖动导致上传文件有延迟。
- 需要优先确保服务的可用性,而异常回滚是一个耗时的操作,故设计为异步的,保证数据的最终一致性。
- 运维下发停止命令后可以停止MQ消费,并将on the fly的数据排干后再停止应用,这样可以有效降低下次启动时巨大的checkpoint恢复成本。
- 遇到HDFS故障时可以将本地磁盘作为暂存,这样可以避免checkpoint因超时失败的问题,并有效降低下次启动时巨大的checkpoint恢复成本。
4. 指标统计
- 如图4所示,TDSort由source、writer、checker三级vertex构成,其中checker按照期望的维度对指标进行汇聚(相当于sql中的group by后组内进行sum),进而可得到相应的指标数据。
- 存储每条指标数据时,同时存储checkpointId和指标发送时间,这样在rollback时根据checkPointId和指标发送时间删除相应记录即可。
5. 数据(负载)倾斜
- 仔细观察会发现,流量倾斜主要发生在Source和Writer节点之间。如下图所示,对于每个gaia集群,我们引入了称之为Router的协调者。每个节点会定期上报IO相关的负载信息到Router,Router会根据最近一段时间的流量情况判断是否有机器的IO高于设定的阈值,如果是的话则找出发数据过来的Source节点,从中找出流量最大的数据通道并进行分裂,将数据分发到负载较低的节点上去,实现IO的负载均衡。
图5 Router调整数据路由过程
6. 故障转移
- TDSort可根据运维下发的指令动态停止某一些Source或者Writer而又不用重启整个应用,这在某些机器故障的情况下非常有用,可以避免成本较高的应用启停,并实现人为控制下的故障和流量转移。
7. Sink(HDFS)性能抖动
- 使用本地磁盘作为暂存,在HDFS性能抖动时将数据存入本地磁盘,不堵塞数据接入,并使checkpoint快速通过。
- 每个节点通过常驻的uploader上传文件,这样可在sort停止后将残留文件也上传到HDFS,确保不丢失数据。
五、总结
新的接入方案在接入成本、接入延迟上都有了较为明显的优化效果,减轻了对统一调度系统的负载压力,并具备了端到端的业务对账能力。在公司开源协同的大背景下,TDBank的hive数据实时接入方案已经应用在pcg数据的接入中,并将逐步替换pcg现有的基于atta的数据接入。对TEG信安数据的接入目前也在进行中,后续我们还计划对现网存量的TDBank数据接入任务也进行迁移。
从0开始打造UI框架:动态化框架Scrollview物理学算法解析