背景
现在系统架构都朝着微服务化,云原生化发展,一个大型的系统光微服务数量有可能多达上百个,再加上多机分布式部署,服务异构等原因,导致系统调用链路只会越来越复杂。
一套大型微服务系统主要由以下几种功能组件构成:
- API 网关,主要做服务接口接入,用户鉴权及认证,角色控制,主流组件有 kong 网关,zuul 网关
- 服务发现注册中心,主要实现服务自动自动发现,服务路由信息维护更新,主流组件有 zookeeper、Eureka
- 后台微服务框架,实现具体后台业务逻辑功能框架,有 spring-boot-web,spring-batch(批处理),golang Gin
- 服务之间 RPC 调用,实现服务请求接口调用,主要有 grpc、http2
- 服务故障熔断及降级,提高系统可用性,当接口请求达到一定阈值或者出现异常响应,在不影响系统主要功能时,可以实现服务熔断或者降级
- 异步消息队列,实现请求削峰平滑,无关业务调用异步执行,避免服务请求过大造成请求积压,从而避免系统雪崩。主要的消息队列有 kafka、rabbitMQ
以简单的电商后台系统为例,用户请求经过 Nginx 转发到后端网关服务
- user_center, 用户中心
- deal_center, 订单中心
- pay_center, 支付后台
- register_center, 服务注册中心
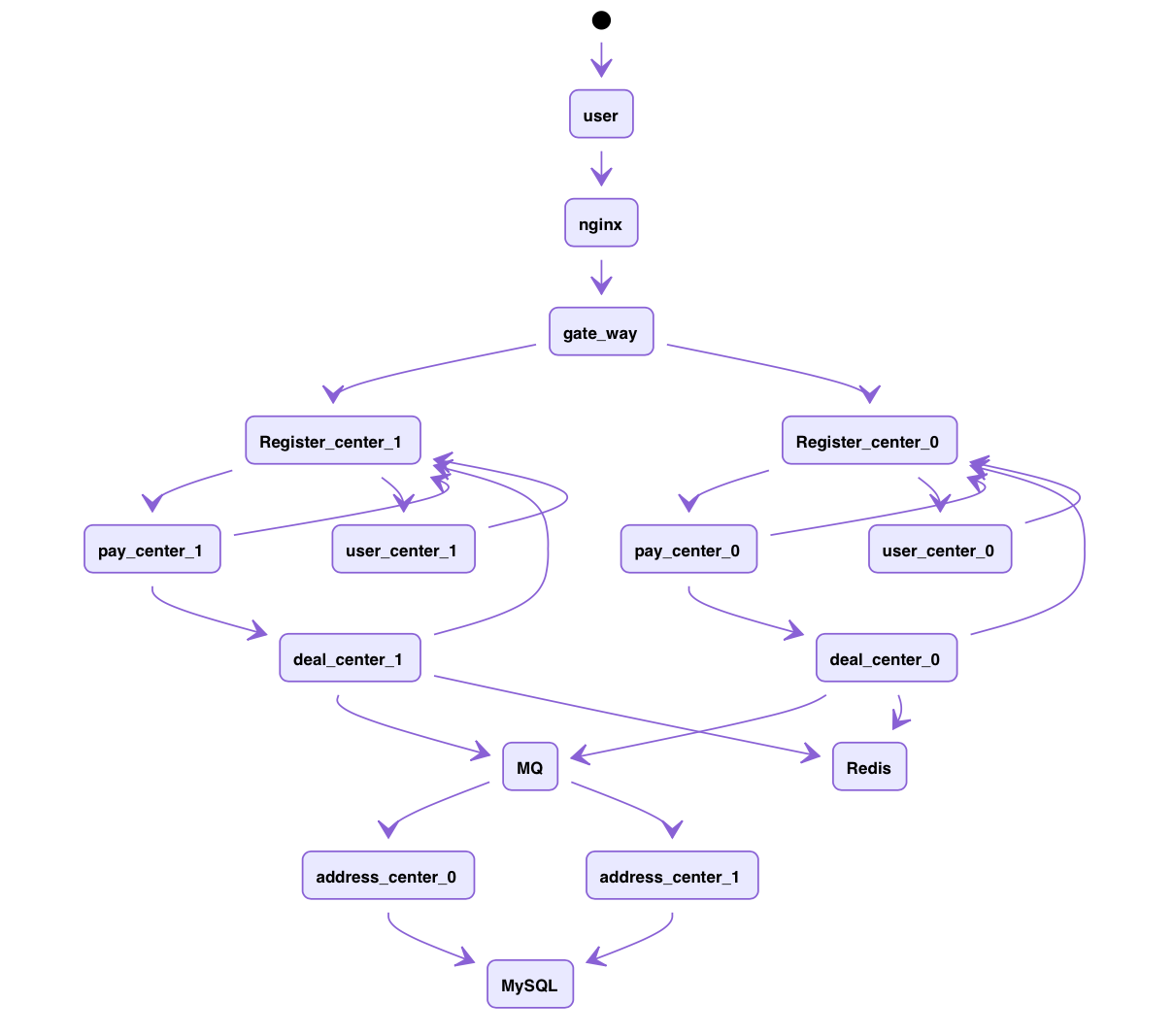
系统之间复杂地调用关系提高了我们排查异常的难度,当系统出现问题,可能需要从上到下,根据请求日志逐级排查,耗时耗力,
正因如此,APM(Application performance management) 也就显得越来越重要,在协助我们分析定位系统问题也是必不可少的。
服务监控介绍
在了解服务监控之前我们先了解下简单的监控概念
- Liveness,存活探针,检测我们服务运行情况,通常为 http 接口,通过接口的返回码判断服务是否正常。
- Span,一次调用我们称为一个 span,span 可以为 RPC 调用,Http 调用,数据库或者 redis 调用等,
Span 通过一个 64 位 ID 唯一标识,Span 还有其他数据信息,比如摘要、时间戳事件、关键值注释 (Tags)、Span 的 ID、以及进度 ID (通常是 IP 地址)。 - Trace,调用树,一系列 span 组成的调用链路,比如一个分布式系统,从用户请求经过各种微服务最终到达数据库,那么这一系列调用组成的链路就称为 trace 树,trace 采用与 span 区别的 64 位 ID 标识。
- Kind,调用方,区别是客户端/服务端调用
监控系统组件及架构
我们从监控系统的数据流程可以将系统分为数据探针、数据采集上报、数据存储、数据分析聚合、数据可视化及监控告警。目前主流的开源系统监控组件主要有
- zipkin 服务调用及链路追踪
- skywalking apache 开源的服务性能监控组件
- prometheus 监控数据采集及告警组件
- grafana 数据可视化分析
- elasticsearch 数据存储及聚合
下面我们分别将这些系统组合起来,因篇幅有限,暂时不展开如何进行定制化开发和适配。
数据采集
首先,我们需要采集系统的原始监控数据。数据采集器主要有类似探针、agent,这里以 zipkin 链路监控为例
在 springboot 微服务中接入 zipkin 只需要引入相应的依赖包
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-zipkin</artifactId>
<version>2.2.4.RELEASE</version>
</dependency>zipkin trace id的生成主要是构建 servlet filter 拦截器,判断是否是上游调用,上游调用就继续沿用trace id,作为客户端调用就继续生成新的span id.
数据上报及存储
为了监控链路的可用性,通常我们会将链路监控等数据写入 kafka,同时从 kafka 读取数据并写入到 elasticsearch 存储中。这样可以避免当我们监控服务异常时,不影响正常服务,同时监控数据还是写入成功,只是暂存在 kafka 等消息中间件中。幸运地是,zipkin 支持多种消息中间件 reporter。
同时,你可以定制开发自己的 sender,在服务初始化时加载自定义的 reporter 组件,这里以数据写入 kafka 为例。
- 添加 maven 依赖
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-zipkin</artifactId>
<version>2.2.4.RELEASE</version>
</dependency>
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
</dependency>- 定制 sender,在配置类中初始化制定 sender 为 kafka sender
@Configuration
public class SenderCustomer {
@Bean
Sender sender(){
return KafkaSender.newBuilder()
.bootstrapServers("xxx.xxx.xxx.xxx:9092,xxx.xxx.xxx.xxx:9092")
.encoding(Encoding.JSON)
.topic("xxx")
.build();
}
}在服务启动之后,我们调用测试接口,可以看到链路数据正确写入 Kafka 中
- 启动 zipkin_server
确认数据正确推送到 Kafka,下面我们启动 zipkin_server,将数据从 Kafka 消费,并存储至 ES。
/**
* @deprecated Custom servers are possible, but not supported by the community. Please use our
* <a href="https://github.com/openzipkin/zipkin#quick-start">default server build</a> first.
* If you find something missing, please <a href="https://gitter.im/openzipkin/zipkin">gitter</a> us
* about it before making a custom server.
*
* <p>If you decide to make a custom server, you accept responsibility for troubleshooting your
* build or configuration problems, even if such problems are a reaction to a change made by the
* Zipkin maintainers. In other words, custom servers are possible, but not supported.
*/从这段注释可以看出,在 zipkin2 后续的版本已经不再推荐自定义 zipkin_server,所以现在建议采用官方发布的 zipkin_server 或者自己 clone 源码本地编译后启动。采用 release zipkin_server 有官方教程 (https://zipkin.io/pages/quickstart),这里展示如何本地编译并启动
git clone https://github.com/openzipkin/zipkin.git
cd zipkin
mvn -DskipTests --also-make -pl zipkin-server clean install
STORAGE_TYPE=elasticsearch ES_SSL_NO_VERIFY=true ES_HOSTS=https://node1.elastic.com:9500,https://node2.elastic.com:9500 ES_HTTP_LOGGING=BASIC ES_USERNAME=elastic ES_PASSWORD=xxx java -jar zipkin-server-2.21.8-SNAPSHOT-exec.jar --zipkin.collector.kafka.enabled=true --zipkin.collector.kafka.bootstrap-servers=xxx.xxx.xxx.xxx:9092 --zipkin.collector.kafka.topic=xxx启动命令指定了 collector 类型为 Kafka,并且配置了相关的 Kafka servers 地址和 topic 值,storage 类型为 elasticsearch
我们可以访问 zipkin_server(http://localhost:9411) 地址,查看我们请求的调用链。
这里可以看到,服务展示了一次请求调用的路由,起始,终止时间,主/被调方,请求结果。
- 查看 Elasticsearch 数据
在 zipkin_server 中我们查看了一次简单的 http 调用的展示界面,接着来看下存储在 ES 中的具体数据格式。一次简单调用的原始数据如下
{
"_index": "zipkin-span-2020-09-23",
"_type": "_doc",
"_id": "3ed3c7897c773c7c-00d8b820e72edda2216dc3328d19c661",
"_version": 1,
"_score": null,
"_source": {
"traceId": "3ed3c7897c773c7c",
"duration": 16591,
"remoteEndpoint": {
"ipv4": "10.43.27.75",
"port": 62422
},
"shared": true,
"localEndpoint": {
"serviceName": "user-info"
},
"timestamp_millis": 1600831775784,
"kind": "SERVER",
"name": "get /get-user-info",
"id": "19ffb94ef8b93d5f",
"parentId": "0e0811feba4614f4",
"timestamp": 1600831775784046,
"tags": {
"http.method": "GET",
"http.path": "/get-user-info",
"mvc.controller.class": "GetUserInfo",
"mvc.controller.method": "getUserInfo"
}
},
"fields": {
"timestamp_millis": [
"2020-09-23T03:29:35.784Z"
]
},
"sort": [
1600831775784
]
}以上,已经验证了数据采集和上报 kafka 的链路。现在我们可以模拟链路之间的调用,这里启动几个简单的后台服务,并分别注册到 Eureka 注册中心,从注册中心可以看到我们的服务主要包括
- gateway 网关
- config server 配置中心
- deal-info 订单中心
- pay-center 支付中心
- user-info 用户中心
数据分析聚合
启动以上服务,通过接口调用,可以检查我们的服务调用关系,可以看到我们的支付中心需要调用订单中心和用户中心,校验用户状态和订单信息。
数据可视化及监控告警
- 建立监控视图
因为数据主要存储在 elasticsearch 中,我们可以通过 kibana 为数据建立监控视图,这里主要创建两个聚合视图,按照请求耗时建立监控曲线,按照 traceId 分组统计请求量。
- 建立监控面板
建立好监控视图之后,我们统计监控面板
通过以上监控面板,可以设置具体的平均请求耗时阈值,超过阈值发送短信邮件告警。
总结
以上,就是简单的系统调用链路监控。当然,我们可以继续搭建更多的监控指标和面板,同时还可以采用不同的监控组件。但是大体监控流程都是类似,主要是:
数据采集探针、数据上报、数据存储、监控视图、系统告警等。
【技术创作101训练营】