一.简介:
最近经常有朋友让我帮忙写个爬虫,便萌生了一个写一篇简单的scrapy教程的想法,旨在帮助没有太多爬虫经验的朋友,可以快速爬取到所需的信息.
本文以爬取清华大学两院院士信息为例,介绍了网页内容爬取,网页图片下载,数据库存储等方法,并将程序部署在了腾讯云轻量应用服务器lighthouse中.
二.环境准备:
本文所需环境包括:
1.lighthouse服务器
这里简单介绍一下lighthouse的购买.先放一段lighthouse官网的简介:
‘‘轻量应用服务器(Lighthouse)是一种易于使用和管理、适合承载轻量级业务负载的云服务器,能帮助中小企业及开发者在云端快速构建网站、博客、电商、论坛等各类应用以及开发测试环境,并提供应用部署、配置和管理的全流程一站式服务,极大提升构建应用的体验,是您使用腾讯云的最佳入门途径.’’
购买地址点击这里
lighthouse提供多种镜像供你选择,这里我们先选择LAMP镜像,选择套餐后进行支付,就拥有了属于你的lighthouse镜像!
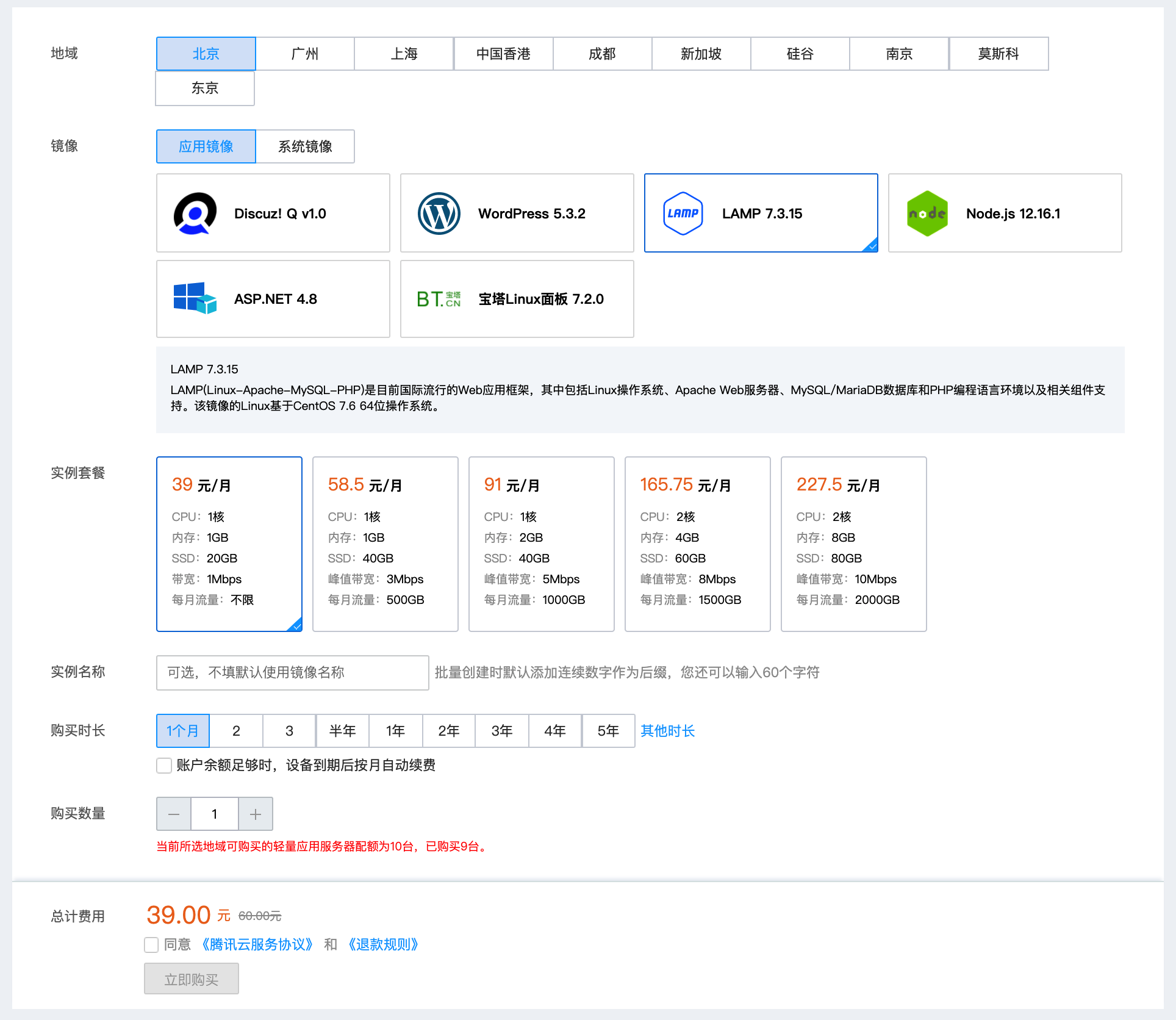
lighthouse购买页
2.Mysql数据库
lighthouse的LAMP镜像中集成了MySQL数据库,可以直接使用,无需再安装MySQL.如果有着更高的存储要求,还可以选择使用云数据库MySQL.本文使用的是云数据库MySQL.
3.Python 3.x
安装Python3这里不加以赘述,网上的教程已经非常详细.
三.编写爬虫
1.安装所需python库:
pip3 install scrapy
pip3 install twisted
pip3 install Pillow
2.新建一个scrapy项目
运行命令scrapy start project lighthousespider,可以看到在当前目录下新建了一个名为lighthousespider的项目,项目的结构如下:
项目结构
其中,spiders文件夹便是我们定义爬取逻辑的位置.本例为清华大学两院院士的爬取,在spiders中新建tsinghua.py,并建立tsinghuaSpider类如下:
class tsinghuaSpider(scrapy.Spider):
name = 'tsinghua'
allowed_domains = ['www.tsinghua.edu.cn']
start_urls = ['https://www.tsinghua.edu.cn/szdw1/jcrc/lyys1.htm', ]
custom_settings = {
}其中,name表示该Spider的标识,allowed_domains表示允许爬取的域名,start_urls表示要爬取的网页的url,custom_setting中定义该Spider单独的设置.
在lighthousespider下,我们新建begin.py,作为爬虫的入口:
from scrapy import cmdline
cmdline.execute("scrapy crawl tsinghua".split())3.设计items
在这一步,我们需要定义我们要爬取的内容.首先,我们需要观察我们需要爬取的网页.
清华大学两院院士页面
可以看到,在清华大学两院院士页面中,展示了院士们的名单,院士们的名字是一个链接.点击之后,是该院士的详细信息.
院士详细信息
在详细信息中,我们可以看到有名字,简介,照片三部分.由此,初步定下我们爬取的信息:姓名,简介,照片.
在items.py中新建一个Item:TsinghuaItem,定义我们需要爬取的信息,并进行初始化:
class TsinghuaItem(scrapy.Item):
teacher_name = scrapy.Field()
content = scrapy.Field()
image_url = scrapy.Field()
def __init__(self):
super(TsinghuaItem, self).__init__()
for key in self.fields:
self._values[key] = ''4.编写爬取逻辑
在刚刚的观察中,我们可以很容易的得到我们爬取的基本逻辑:循环点击每一位院士的名字,进入该院士的详情页->爬取姓名,简介,照片.
回到清华大学两院院士页面,进入开发者模式,找到院士们名字的href:
找名字的href
在tsinghuaSpider类中复写parse方法,使用CSS选择器得到我们需要的元素.不会CSS语法也没关系,Google一下就可以了,非常的简单.姓名的href使用的是相对值,因此,我们还需要把href和当前url进行结合,得到绝对地址url,发起一个Request,并指定回调函数为parse_detail,使用parse_detail作为详情页的处理函数:
def parse(self, response, **kwargs):
href_list = response.css('div.yuanShi a::attr(href)').extract()
for href in href_list:
yield Request(url=urljoin(get_base_url(response), href), callback=self.parse_detail)类似地,我们进入院士的详情页,找到姓名,简介,照片所在的元素:
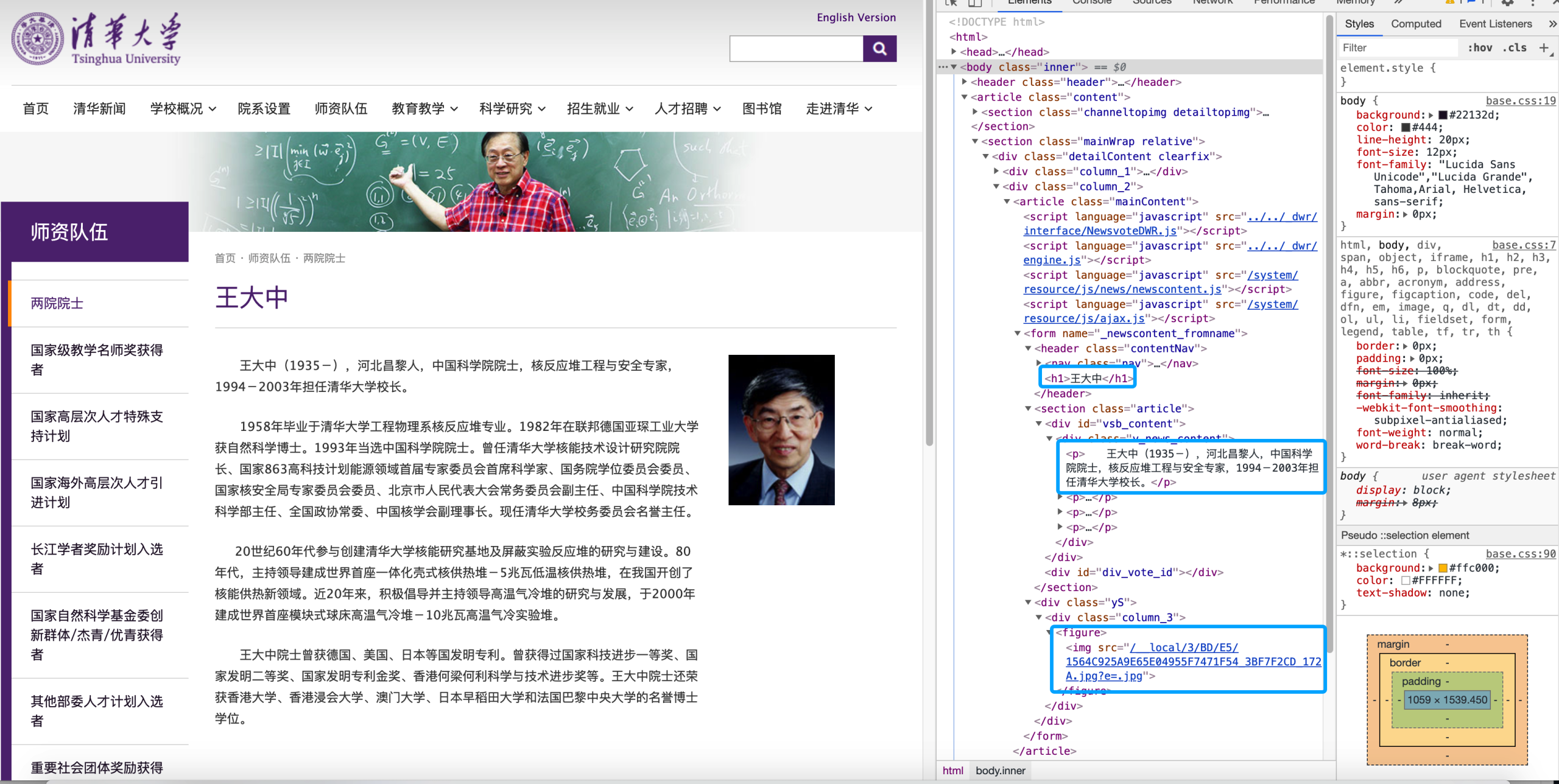
添加描述
在parse_detail函数中,我们使用CSS选择器得到我们所需的值,并将其放入到之前定义好的TsinghuaItem中,进行提交.为了去除多余的空格,换行等字符,我们还定义了函数trim:
def parse_detail(self, response, **kwargs):
teacher_name = self.trim(str(response.css('header.contentNav h1::text').extract()))
content = self.trim(str(response.css("div.v_news_content *::text").extract()))
image_url = urljoin(get_base_url(response), str(response.css('div.yS img::attr(src)').extract()))
item = TsinghuaItem()
item['teacher_name'] = teacher_name
item['content'] = content
item['image_url'] = image_url
yield item@staticmethod
def trim(value: str):
if value is None:
return ''
bad_chars = ['\n', '\t', '\u3000', '\xa0', ' ', '\r', ' ']
for char in bad_chars:
value = value.replace(char, '')
return value.strip()至此,我们得到了院士的姓名,简介,和照片的url.
5.下载照片
我们需要通过爬取到的照片的url,下载院士的照片,并存储在本地.scrapy在pipelines中提供了ImagesPipeline,我们只要继承ImagesPipeline,并简单的复写一下就可以了:
class MyImagesPipeline(ImagesPipeline):
store_uri = None
def __init__(self, store_uri, download_func=None, settings=None):
self.store_uri = store_uri
super(MyImagesPipeline, self).__init__(store_uri, settings=settings,download_func=download_func)
def get_media_requests(self, item, info):
image_url = item['image_url']
if image_url:
yield scrapy.Request(image_url)定义了MyImagesPipeline后,还需要将其加入到settings中使其生效.我们可以选择在settings.py中,取消掉ITEM_PIPELINES的注释,加入MyImagesPipeline,并设立该pipelines的优先级,优先级表示多个pipelines时调用的顺序,数字越小表示优先级越高:
ITEM_PIPELINES = {
'lighthousespider.pipelines.MyImagesPipeline': 400,
}我们还可以在之前提到的custom_settings中加入MyImagesPipeline:
custom_settings = {
'ITEM_PIPELINES': {
'lighthousespider.pipelines.MyImagesPipeline': 400,
},
}两种方式的区别为:在custom_settings中添加的pipelines仅作用于当前Spider,而在settings.py中添加的pipelines作用于所有Spider.
添加完pipelines后,我们在settings.py中配置照片的存储路径:
#image store
IMAGES_URLS_FIELD = "image_url"
project_dir = os.path.abspath(os.path.dirname(__file__)) #获取当前爬虫项目的绝对路径
IMAGES_STORE = os.path.join(project_dir, 'images') #组装新的图片路径运行begin.py,可以看到在lighthousespider下建立了images文件夹,存储了院士们的照片:
院士照片
6.数据存储
爬取到数据后,我们需要将其存入到数据库.首先,我们需要在MySQL中配置库和表.我们建立一个名为tsinghua的数据库,并设计tsinghua_teacher表如下:
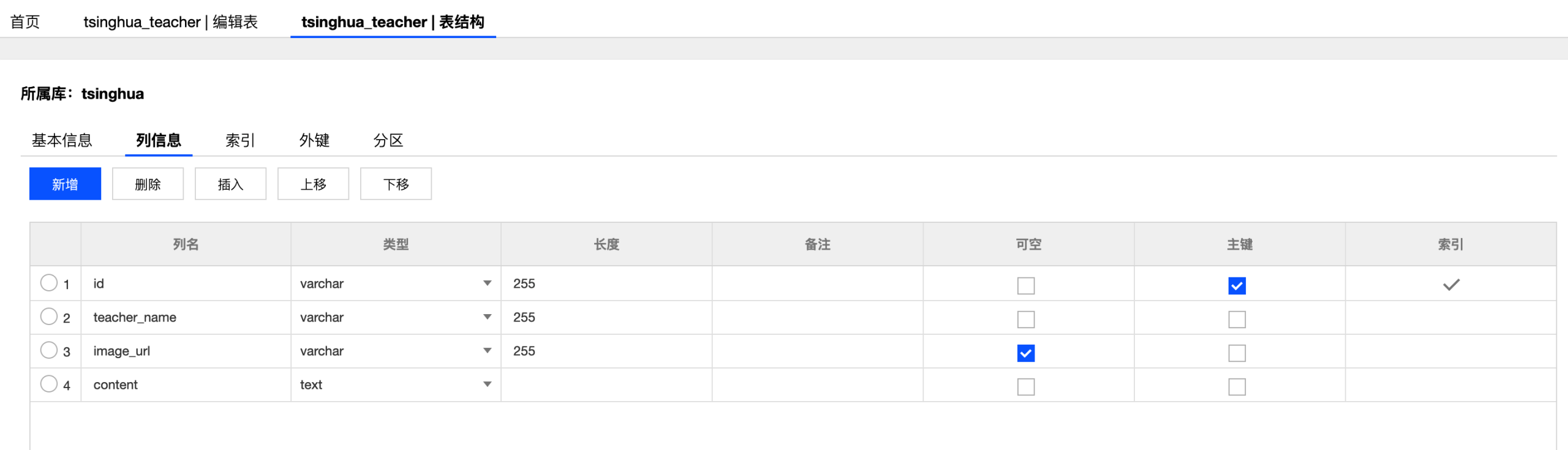
tsinghua_teacher表结构
在settings.py中,我们需要定义我们数据库的连接信息:
#Mysql数据库的配置信息
MYSQL_HOST = '111.111.111.111' #数据库地址
MYSQL_DBNAME = 'tsinghua' #数据库名字
MYSQL_USER = 'root' #数据库账号
MYSQL_PASSWD = '*********' #数据库密码
MYSQL_PORT = 3306 #数据库端口在pipelines.py中,我们定义一个新的pipeline:InsertDBPipeline,通过twisted连接到MySQLdb.值得注意的是,在Python3当中使用的是pymysql,而非MySQLdb,因此我们还需要做一个转换:
import pymysql
pymysql.install_as_MySQLdb()class InsertDBPipeline(object):
def __init__(self, dbpool):
self.dbpool = dbpool
def process_item(self, item, spider):
query = self.dbpool.runInteraction(self._conditional_insert, item)
query.addErrback(self._handle_error, item, spider)
return item
@classmethod
def from_settings(cls, settings):
dbparams = dict(
host=settings['MYSQL_HOST'],
db=settings['MYSQL_DBNAME'],
user=settings['MYSQL_USER'],
passwd=settings['MYSQL_PASSWD'],
charset='utf8',
use_unicode=False,
)
dbpool = adbapi.ConnectionPool('MySQLdb', **dbparams)
return cls(dbpool)
def _conditional_insert(self, tx, item):
id = str(uuid.uuid1())
sql = "insert into tsinghua_teacher" \
"(id, teacher_name, image_url, content)" \
"values(%s,%s,%s,%s)"
params = (id, item['teacher_name'], item['image_url'], item['content'])
tx.execute(sql, params)
def _handle_error(self, failue, item, spider):
print(failue)最后,和MyImagesPipeline类似,我们还需要在settings.py或者custom_settings中添加新定义的pipeline:
custom_settings = {
'ITEM_PIPELINES': {
'lighthousespider.pipelines.MyImagesPipeline': 400,
'lighthousespider.pipelines.InsertDBPipeline': 300
},
}运行begin.py,可以看到数据库表中数据如下:
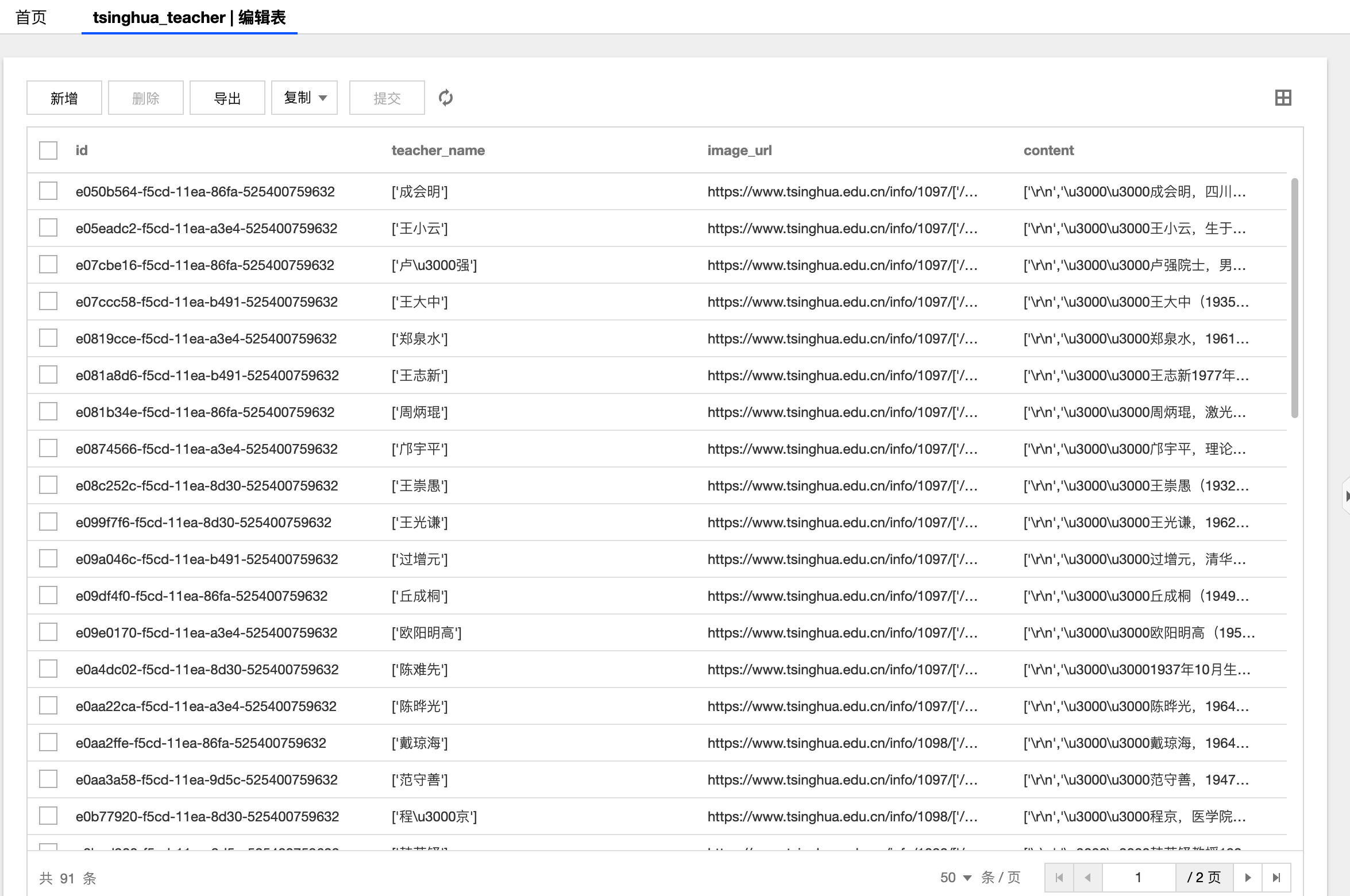
院士数据
至此,爬虫运行结束,我们已经得到了我们想要的数据
四.小结
在本文中,我们以爬取清华大学两院院士信息为例,详细的介绍了scrapy爬虫的编写,希望能对刚刚接触爬虫的朋友们有所帮助.
本文介绍的内容以爬虫入门为主,较为简单.在之后的文章中,我会详细介绍一些相对复杂的爬虫技术,包括爬取javascript动态渲染页面,设立请求代理池,ip池,cloudflare5秒盾破解等等,敬请期待.