笔者从业以来一直关注国产数据库的发展,以及各大公司在开源数据库领域的工作,很高兴能看到国产数据库在开源领域又填新丁:TBase。TBase已于2019年11月正式开源。2020年7月13日,TBase发布了开源版本2.1.0,该版本在多活分布式能力、性能、安全性、可维护性等多个关键领域得到全面的增强和升级。
PS:测评体验主要基于TBase最新的开源版本2.1.0。笔者本身从事的OLAP的数据库系统开发,所以本次测评会更多从分析型数据库的角度来审视TBase。由于笔者水平有限,文章难免有错漏之处,烦请斧正。
1.What’s TBase ?
TBase是腾讯基于PostgreSQL研发的一个分布式HTAP数据库,适用于拥有海量数据、高并发、部分分析场景解决,以及分布式事务能力的应用场景。 从现有的资料来看,TBase本身在腾讯内部是经过业务长期迭代打磨的产品,目前在腾讯云上也提供商业化的版本销售。
1.1 TBase的架构
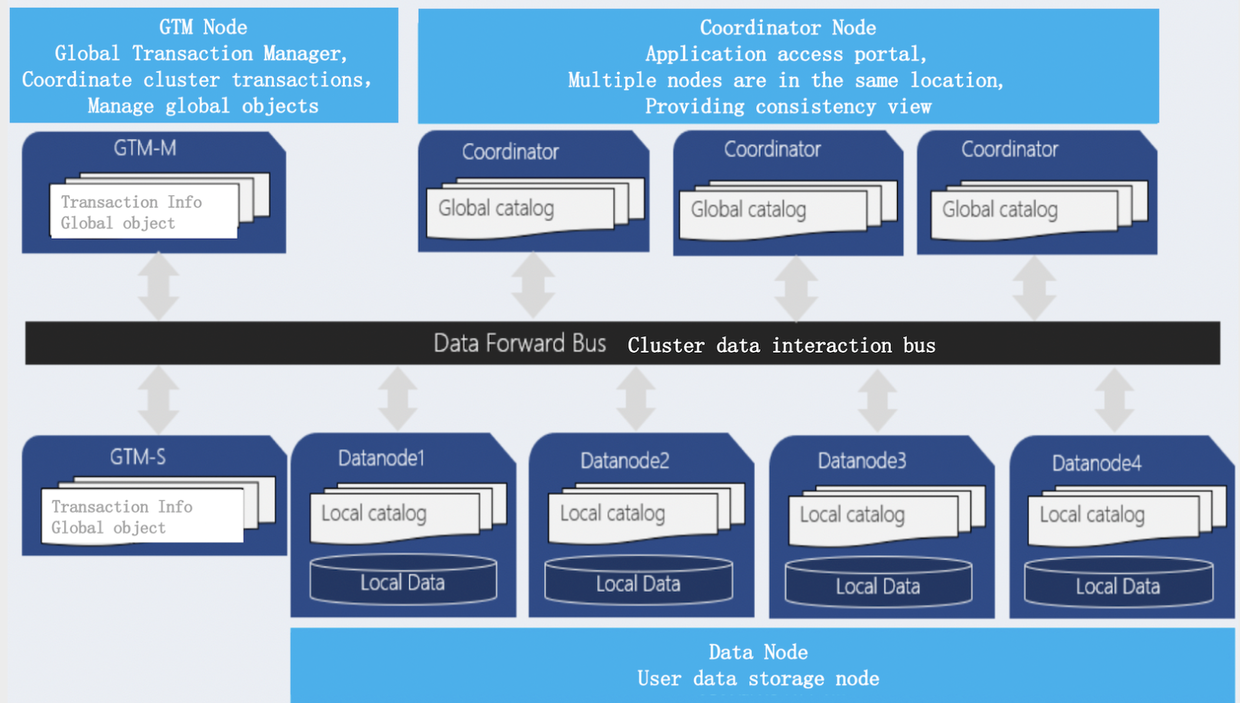
如图所示, TBase是一个典型的Shared Nothing的MPP数据库,它由三个部分组成:
- GlobalTransactionManager(简称为 GTM), 是一个全局事务管理器,负责全局事务管理。同时它也作为一个GTS(时钟服务器)来发布全局的事务时间戳。
- Coordinator
Coordinator 是协调节点, 是数据库统一的对外入口。协调节点接受用户的SQL请求,解析SQL生成分布式执行计划。它存储系统的元数据,并不存储实际的业务数据,可以配合支持业务接入增长动态增加。 - Datanode
Datanode是数据节点,执行协调节点分发的执行计划,并分配资源执行该分布式执行计划。每个Data Node运行独立的PostgreSQL的节点,进行实际业务数据的存储。
2.TBase初体验
实践是检验真理的唯一标准,接下来我们直奔主题,开始TBase的试用体验。
2.1 编译安装
TBase的编译安装流程主要参考以下官方Wiki:
整个TBase编译安装的过程和PostgreSQL-XC几乎大同小异,坦白说,相对来说这个过程对于没有PostgreSQL背景的新手来说还是略显复杂了。
这个中途还有一个小插曲,笔者在编译过程之中发现了一个PostgreSQL的编译Bug。PostgreSQL官方已经修复该编译Bug了,于是笔者也给TBase官方提交了修复PR,好在TBase的同学很快响应并进行了代码合入,感兴趣的同学可以参考这个链接:issues:72
这是笔者安装完成后集群的拓扑结构:
|
Host |
Type |
Port |
|---|---|---|
|
192.168.1.116 |
GTM Primary |
50001 |
|
192.168.1.115 |
GTM Replica |
50001 |
|
192.168.1.116 |
CN1 |
30001 |
|
192.168.1.115 |
CN2 |
30001 |
|
192.168.1.116 |
DN1 Primary |
40001 |
|
192.168.1.116 |
DN1 Replica |
40000 |
|
192.168.1.115 |
DN2 Primary |
40001 |
|
192.168.1.115 |
DN2 Replica |
40000 |
3 深度测评
笔者将从多个方面,站在一个数据库使用者的角度来尝试测评TBase。管中窥豹,可见一斑,我们开始吧。
3.1 牛刀小试
先通过一些例子数据进行一些初体验。先建立如下表,并插入测试数据
create table foo(
id bigint, str text
) distribute by shard(id);
insert into foo values(1, 'tencent'), (2, 'shenzhen');3.1.1 数据shard测试
看一看简单查询语句的执行计划
explain select * from foo;
QUERY PLAN
---------------------------------------------------------------
Remote Fast Query Execution (cost=0.00..0.00 rows=0 width=0)
Node/s: dn001, dn002
-> Seq Scan on foo (cost=0.00..18.80 rows=880 width=40)
(3 rows)查询正常分配到两个数据节点之上了,这个符合shard分片的数据扫描逻辑。但是这里明明笔者表中只有两行数据,但是这里判别为了880行?
test=> analyze foo;
ANALYZE
test=> explain select * from foo;
QUERY PLAN
---------------------------------------------------------------
Remote Fast Query Execution (cost=0.00..0.00 rows=0 width=0)
Node/s: dn001, dn002
-> Seq Scan on foo (cost=0.00..20.02 rows=2 width=16)
(3 rows)手动analyze之后,恢复正常了。
继续进行我们数据分片的体验,执行下列语句
test=> explain select * from foo where id = 1;
QUERY PLAN
---------------------------------------------------------------
Remote Fast Query Execution (cost=0.00..0.00 rows=0 width=0)
Node/s: dn001
-> Seq Scan on foo (cost=0.00..20.02 rows=1 width=16)
Filter: (id = 1)
test=> explain select * from foo where id = 2;
QUERY PLAN
---------------------------------------------------------------
Remote Fast Query Execution (cost=0.00..0.00 rows=0 width=0)
Node/s: dn001
-> Seq Scan on foo (cost=0.00..20.02 rows=1 width=16)
Filter: (id = 2)我们可以看到过滤条件被分片裁剪了,同时只下推都了一个节点dn001上了,表现不错。
然后我们加大一些难度,我们将上两个查询的过滤条件作为or 拼接起来试一试:
test=> explain select * from foo where id = 2 or id = 1;
QUERY PLAN
---------------------------------------------------------------
Remote Fast Query Execution (cost=0.00..0.00 rows=0 width=0)
Node/s: dn001, dn002
-> Seq Scan on foo (cost=0.00..20.03 rows=2 width=16)
Filter: ((id = 2) OR (id = 1))囧rz,TBase没能感知到这个两个条件都应该在同一个节点上,一股脑的推到所有节点上了,看来Tbase的Shard逻辑与查询规划的优化还有提升的空间。
小结
Tip 1:由于TBase是基于COST模型进行优化的,所以对应查询性能敏感的语句,尽量在使用前进行analyze.
Tip 2:TBase在数据分片列上只能选择单列,这个是笔者无法理解的。本身通过Hash分区就是计算hash值,原则上多列和单列实现上应该没有二致。所以在使用时,大家尽量选择区分度较大的列作为分片列。
Tip 3:目前看起来TBase的优化器感知数据分片的能力还是有所欠缺的,期许改进。
3.1.2 Join 小测
对一个数据库来说,Join 的查询规划是及其考验其优化器实现功力的一项重要内容,我们来看看TBase的表现吧。
再次建立一张新的空表:
create table foo1(
id bigint, str text
) distribute by shard(id);尝试执行表foo与foo1的join,这里通过分区列id作为等值join的条件
explain select * from foo, foo1 where foo.id = foo1.id;
QUERY PLAN
-----------------------------------------------------------------------
Remote Fast Query Execution (cost=0.00..0.00 rows=0 width=0)
Node/s: dn001, dn002
-> Hash Join (cost=20.04..42.23 rows=9 width=56)
Hash Cond: (foo1.id = foo.id)
-> Seq Scan on foo1 (cost=0.00..18.80 rows=880 width=40)
-> Hash (cost=20.02..20.02 rows=2 width=16)
-> Seq Scan on foo (cost=0.00..20.02 rows=2 width=16)是一个普通的Hash Join,但是空表的条目数依旧判别为了880条,笔者尝试analyze之后也无改变。TBase是基于CBO进行优化的,如果表的信息不准确,那边很难进行到正确的查询规划。这里的Hash Join左右表的选择是错误的,很难得到一个高效率的查询结果。
再次尝试执行表foo与foo1的join,这里通过非分区列str作为等值join的条件:
test=> explain select * from foo, foo1 where foo.str = foo1.str;
QUERY PLAN
----------------------------------------------------------------------------------------------------
Remote Subquery Scan on all (dn001,dn002) (cost=20.04..42.23 rows=9 width=56)
-> Hash Join (cost=20.04..42.23 rows=9 width=56)
Hash Cond: (foo1.str = foo.str)
-> Seq Scan on foo1 (cost=0.00..18.80 rows=880 width=40)
-> Hash (cost=120.06..120.06 rows=2 width=16)
-> Remote Subquery Scan on all (dn001,dn002) (cost=100.00..120.06 rows=2 width=16)
-> Seq Scan on foo (cost=0.00..20.02 rows=2 width=16)出现了Remote SubQuery, 可见非分区列的join是更为消耗资源,也是更慢的。
然后我们加大一些难度,重新建立一张空的新表foo2,执行下列查询:
explain select * from foo, foo1, foo2 where foo.str = foo1.str and foo.id = foo1.id and foo1.id = foo2.id;
QUERY PLAN
-----------------------------------------------------------------------------------
Remote Fast Query Execution (cost=0.00..0.00 rows=0 width=0)
Node/s: dn001, dn002
-> Hash Join (cost=45.47..67.61 rows=4 width=96)
Hash Cond: (foo2.id = foo.id)
-> Seq Scan on foo2 (cost=0.00..18.80 rows=880 width=40)
-> Hash (cost=45.46..45.46 rows=1 width=56)
-> Hash Join (cost=20.05..45.46 rows=1 width=56)
Hash Cond: ((foo1.str = foo.str) AND (foo1.id = foo.id))
-> Seq Scan on foo1 (cost=0.00..18.80 rows=880 width=40)
-> Hash (cost=20.02..20.02 rows=2 width=16)
-> Seq Scan on foo (cost=0.00..20.02 rows=2 width=16)TBase规划出了两级的Hash Join查询,并且优先进行了大小表的查询,同时也能感知到join条件列之中的shard列信息,这个多表查询的规划结果符合我们的预期。
小结
Tip 1:通过Shard列进行Join能够大大优化实际生成的查询规划,所以尽量进行Shard列的Join查询.
3.2 星型模型测试
通过上节的简单测试,可以反馈出部分TBase的表现了。接下来我们引入更为专业的星型模型测试对TBase进行测评。
关于星型模型
SSB(Star Schema Benchmark)是一个经典的基于现实商业应用的数据库模型,业界公认的一个OLAP的测试标准。
SSB基准测试包括:
事实表:lineorder
维度表:dates, customer,part, supplier
涉及了多个纬度的数据库查询能力的反馈,它能很好的展现出数据库在分析上的能力,所以我们依托与它的数据来产出数据。关于星型模型的具体使用方式可以参考如下链接:Star Schema Benchmark,SSB生成的数据是CSV格式的,这部分可以通过copy命令导入TBase。
3.2.1 多核并行计算能力测试
星型模型测试是一个典型的OLAP的测试数据集合,对一个数据库系统的多核并行计算能力有很高的要求,我们来看看TBase的表现。
我们以SSB的Query 1.1作为基准,由于TBase是默认开启并行执行的,我们先将TBase的多核并行的关闭,并查看该查询的执行计划:
postgres=# set max_parallel_workers_per_gather = 0;
SET
postgres=# explain SELECT SUM(LO_EXTENDEDPRICE*LO_DISCOUNT) AS
REVENUE
FROM LINEORDER, DATES
WHERE LO_ORDERDATE = D_DATEKEY
AND D_YEAR = 1993
AND LO_DISCOUNT BETWEEN 1 AND 3
AND LO_QUANTITY < 25;
QUERY PLAN
-----------------------------------------------------------------------------------------------------------------
Finalize Aggregate (cost=238924.50..238924.51 rows=1 width=32)
-> Remote Subquery Scan on all (dn001,dn002) (cost=238924.49..238924.50 rows=1 width=0)
-> Partial Aggregate (cost=238824.49..238824.50 rows=1 width=32)
-> Hash Join (cost=193.03..238824.49 rows=223594 width=16)
Hash Cond: (lineorder.lo_orderdate = dates.d_datekey)
-> Seq Scan on lineorder (cost=0.00..232481.09 rows=782887 width=20)
Filter: ((lo_discount >= 1) AND (lo_discount <= 3) AND (lo_quantity < 25))
-> Hash (cost=290.47..290.47 rows=730 width=4)
-> Remote Subquery Scan on all (dn001,dn002) (cost=100.00..290.47 rows=730 width=4)
-> Seq Scan on dates (cost=0.00..183.90 rows=730 width=4)
Filter: (d_year = 1993)通过查询计划我们可以看到,TBase没有进行Parallel的操作。
我们再重新开启多核并行,再次观察TBase的查询计划:
postgres=# set max_parallel_workers_per_gather = 2;
SET
postgres=# explain SELECT SUM(LO_EXTENDEDPRICE*LO_DISCOUNT) AS
REVENUE
FROM LINEORDER, DATES
WHERE LO_ORDERDATE = D_DATEKEY
AND D_YEAR = 1993
AND LO_DISCOUNT BETWEEN 1 AND 3
AND LO_QUANTITY < 25;
QUERY PLAN
-------------------------------------------------------------------------------------------------------------------------
-------
Parallel Finalize Aggregate (cost=175540.41..175540.42 rows=1 width=32)
-> Parallel Remote Subquery Scan on all (dn001,dn002) (cost=175540.29..175540.40 rows=1 width=0)
-> Gather (cost=175440.29..175440.40 rows=1 width=32)
Workers Planned: 2
-> Partial Aggregate (cost=174440.29..174440.30 rows=1 width=32)
-> Parallel Hash Join (cost=193.03..173974.47 rows=93164 width=16)
Hash Cond: (lineorder.lo_orderdate = dates.d_datekey)
-> Parallel Seq Scan on lineorder (cost=0.00..171218.79 rows=326203 width=20)
Filter: ((lo_discount >= 1) AND (lo_discount <= 3) AND (lo_quantity < 25))
-> Parallel Hash (cost=290.47..290.47 rows=730 width=4)
-> Parallel Remote Subquery Scan on all (dn001,dn002) (cost=100.00..290.47 rows=730 wi
dth=4)
-> Seq Scan on dates (cost=0.00..183.90 rows=730 width=4)
Filter: (d_year = 1993)
(13 rows)开启并行执行之后,TBase在Query 1.1上有15%左右的性能提升,由于笔者仅有两台虚拟机作为集群,相信在更多数据节点的加持下,并行化的效果会更加显著:
|
|
非并行 |
并行 |
|---|---|---|
|
查询耗时 |
2109.242 ms |
1776.838 ms |
小结
Tip 1:在能开启多核并行执行的场景下,尽量开启,能够优化TBase的查询效率。但是需要注意监控多查询并发执行时数据库系统的压力变化。
3.2.2 非join查询转化join能力
在数据库之中,能够将非join查询转换为join是考验数据库优化器的一项重要的观察指标。一起来看看TBase的表现吧:
我们以SSB的Query 1.1作为基准,将这个查询做一个小的修改,改为查询发生在1992年一月的所有订单,所以我们执行以下查询:
postgres=# explain SELECT SUM(LO_EXTENDEDPRICE*LO_DISCOUNT) AS
REVENUE
FROM LINEORDER
WHERE LO_ORDERDATE in (select D_DATEKEY from DATES where D_DATEKEY >= 19920101 and D_DATEKEY <= 19920131)
AND LO_DISCOUNT BETWEEN 1 AND 3
AND LO_QUANTITY < 25;
QUERY PLAN
-------------------------------------------------------------------------------------------------------------------------
------
Parallel Finalize Aggregate (cost=173497.39..173497.40 rows=1 width=32)
-> Parallel Remote Subquery Scan on all (dn001,dn002) (cost=173497.27..173497.39 rows=1 width=0)
-> Gather (cost=173397.27..173397.38 rows=1 width=32)
Workers Planned: 2
-> Partial Aggregate (cost=172397.27..172397.28 rows=1 width=32)
-> Parallel Hash Semi Join (cost=197.34..172361.34 rows=7186 width=16)
Hash Cond: (lineorder.lo_orderdate = dates.d_datekey)
-> Parallel Seq Scan on lineorder (cost=0.00..171218.79 rows=326203 width=20)
Filter: ((lo_discount >= 1) AND (lo_discount <= 3) AND (lo_quantity < 25))
-> Parallel Hash (cost=297.16..297.16 rows=53 width=4)
-> Parallel Remote Subquery Scan on all (dn001,dn002) (cost=100.00..297.16 rows=53 wid
th=4)
-> Seq Scan on dates (cost=0.00..196.68 rows=53 width=4)
Filter: ((d_datekey >= 19920101) AND (d_datekey <= 19920131))从查询计划上看,原先的in操作符被改写为了Semi Join。显然通过Semi Join来进行查询执行是比in更为高效的,这里TBase完成的符合咱们的预期。
接下来把in改为not in,重新来看看TBase的表现吧
postgres=# explain SELECT SUM(LO_EXTENDEDPRICE*LO_DISCOUNT) AS
REVENUE
FROM LINEORDER
WHERE LO_ORDERDATE not in (select D_DATEKEY from DATES where D_DATEKEY >= 19920101 and D_DATEKEY <= 19920131)
AND LO_DISCOUNT BETWEEN 1 AND 3
AND LO_QUANTITY < 25;
QUERY PLAN
-------------------------------------------------------------------------------------------------------------------------
----------
Parallel Finalize Aggregate (cost=179582.48..179582.49 rows=1 width=32)
-> Parallel Remote Subquery Scan on all (dn001,dn002) (cost=179582.36..179582.48 rows=1 width=0)
-> Gather (cost=179482.36..179482.47 rows=1 width=32)
Workers Planned: 2
-> Partial Aggregate (cost=178482.36..178482.37 rows=1 width=32)
-> Parallel Seq Scan on lineorder (cost=196.81..177666.85 rows=163101 width=16)
Filter: ((NOT (hashed SubPlan 1)) AND (lo_discount >= 1) AND (lo_discount <= 3) AND (lo_quanti
ty < 25))
SubPlan 1
-> Remote Subquery Scan on all (dn001,dn002) (cost=0.00..196.68 rows=53 width=4)
-> Seq Scan on dates (cost=0.00..196.68 rows=53 width=4)
Filter: ((d_datekey >= 19920101) AND (d_datekey <= 19920131))显然,这一次TBase的表现就没有那么智能了。在显然不存在NULL值的情况下,此时选择Anti Join是更为好的执行计划选择。
小结
Tip 1:希望TBase能将Semi Join转换的兄弟Anti Join也能一起支持起来。
3.2.3 复制表关联查询
TBase支持Brocast Join,也就是复制表的Join。可以将小表以多个副本的方式分散到集群之中。每个节点上都有对应表的全量数据,这样能避免额外的网络开销,并带来可观Join的性能提升。SSB之中,除了Order表作为事实表较为庞大之外,其他的维度表都可以作为复制表存在,所以我们来试一试这个功能。
先在非复制表的情况下进行查询执行:
REVENUE
FROM LINEORDER, DATES
WHERE lo_custkey = d_holidayfl
AND D_YEAR = 1993;
revenue
-------------
24304858700
(1 row)
Time: 3239.929 ms (00:03.240)接下来笔者选取了Date表作为复制表,重建它,并重新导入数据。然后重新运行上面的查询:
postgres=# SELECT SUM(LO_EXTENDEDPRICE*LO_DISCOUNT) AS
REVENUE
FROM LINEORDER, DATES
WHERE lo_custkey = d_holidayfl
AND D_YEAR = 1993;
revenue
-------------
24304858700
(1 row)
Time: 1535.882 ms (00:01.536)我们可以看到,相对与没有使用复制表的查询,性能提升了接近50%,这样的性能提升还是非常可观的。
|
|
非复制表 |
复制表 |
|---|---|---|
|
查询耗时 |
3239.929 ms |
1535.882 ms |
小结
Tip 1:复制表虽然带来了可观的性能提升,同时也引入了较高的存储和数据更新的代价,所以在生产环境之中应该谨慎评估使用。
Tip 2: TBase可以考虑更为激进的复制表方案,例如类似Clickhouse的内存引擎,将复制表直接存在内存之中。
Tip 3: 同样的Brocast Join也可通过分区表实现,只不过需要引入右表的网络传输开销,在右表较小的情况下,未必是不可接受的方案。
4 总结
Tbase作为国产开源数据库的新成员,还是给笔者带来了一些不同解决问题的思路。通过基于基于PostgreSQL的生态,给它的使用和开发都带来了极大的便利性。但是同时TBase也存在一些问题:
- 开源社区不活跃,文档匮乏。:在整个测评进行过程之中,笔者很多问题的解决都是通过搜索PostgreSQL的文档。这对于毫无PostgreSQL使用经验的新手来说是非常不友好的。希望TBase能够加强文档建设,同时利用好开源社区的力量,实现和云版本的互相促进的优势。
- 开源版本功能不全:TBase没有提供类似TiSaprk的工具,同时也不支持列存储,在OLAP的应用上并没有优势。同时由于缺少了OSS平台,这会给在实际生产环境之中的使用带来极大的困难。
- 部分功能较为难以应用: 一些功能存在比较古怪的情况,新建表的条目数目总是880行,尝试
analyze之后也没有相应的变化等。笔者限于机器有限,没有进行冷热数据的测评。这部分需要修改配置文件对数据节点进行重启,这个逻辑看起来是不合理的,希望后续能进行改进。
最后,祝福TBase无论是开源还是云上的版本能够不断迭代成熟,为国产数据库的发展提供动力。共勉~~