机器之心报道
作者:陈萍
谢邀!知乎 CTO 来分享下内容社区的 AI 架构搭建与应用。
「在信息爆炸的互联网海洋中,有价值的信息仍然是稀缺的」。知乎的诞生源于这样一个非常简单的初心。
而在挖掘真正有价值的信息过程中,知乎很好地利用了 AI 技术。
在今年上海召开的 2020 世界人工智能大会云端峰会开发者日「企业及 AI 架构专场」分论坛上,知乎合伙人、首席技术官李大海老师为分享了知乎作为一个内容社区,在 AI 架构上的搭建和应用。
李大海老师拥有多年的搜索算法经验,曾担任 Google 中国软件工程师,云云网工程总监,并曾担任豌豆荚搜索技术负责人,让豌豆荚成为最早涉足应用内搜索和 Deep Link 的公司。
2015 年李大海以合伙人身份加入知乎,先后负责知乎广告技术团队、数据、算法业务。在出任 CTO 之后,李大海统筹负责包括大数据团队、内容流通、AI 新业务拓展等在内的知乎整体技术业务。

以下为演讲主要内容,机器之心进行了不改变原意的整理:
大家好,我是李大海。很荣幸代表知乎来世界人工智能大会开发者日做分享。特殊时期,以这种特殊的方式跟大家作交流,心情是很复杂的。2020 年上半年是非常不容易的半年,不过我们也很高兴地看到,很多企业通过技术创新应对疫情,帮助大家维持正常的工作和生活。知乎也是其中的一员。
从 2016 年引入机器学习以来,AI 技术已经在知乎社区很多环节扎下根。以前我们讲算法讲得比较多,今天我想重点说一下我们在 AI 架构的搭建和应用上的经验。
在知乎,我们的 AI 架构的不同是由不同的 AI 场景和实践催生的。当然,介绍这些应用场景之前,我们应该先简单了解一下知乎。知乎是一个内容社区,包括问答、热榜、知识服务、圈子、直播等等各种产品功能和业务板块,沉淀了数亿的问题、回答、专栏、电子书等等内容,这些内容每天都在被生产、分享、消费。对于一个平台来说,是一个浩大的工程。为了让内容在社区运转得更高效,知乎引入了 AI 技术。
到目前为止,知乎的 AI 应用已经触及到业务的方方面面,并且在实践的过程中,逐步形成几个不同的算法框架。
基础 AI 架构
首先是基础 AI 架构。2017 年,知乎成立专门的 AI 团队,为各个业务提供一个基础算法能力输出。这个团队基于知乎海量的内容及用户行为数据,通过数据挖掘、机器学习、自然语言处理等技术,精准、全面地理解内容及用户,并将基础算法能力以标准统一的形式输出,为公司各业务赋能。
AI 团队自成立以来,为各种不同的业务提供了非常多的应用。随着时间的推移,也产生了一些痛点。比如说,由于没有统一的系统开发框架,各个业务模块和子项目都是单点作战,只有一个同事清楚业务细节,并且新建一个项目要写很多和业务无关脚手架类型的代码。再比如,有的线上代码没经过代码审核、存在非主干分支发布、个人仓库开发等问题,非常不利于协同和维护。另外,服务和模块的复用性比较低,有些常用的逻辑,比如识别打压大话题,被多人、多项目分别实现。另外,像监控不完善,部分问题发现不及时等等,都是小应用太多带来的问题。
因此,急需统一的系统架构来整合所有资源,搭建稳定的基础架构,加速 AI 技术积累并助力业务创新。
我们首先考虑设计统一的基础服务架构,统一定义基础 AI 算法的工作流和数据流。有了这个统一框架之后,很方便在框架上添加监控、报警等等功能,及时发现可能出现的问题,提高服务质量、稳定性和可用率。
在设计良好的架构和统一代码管理的模式下,方便我们去构建这个场景下的通用代码库,提高基础功能的代码复用率,并解决项目和代码的散乱问题。
在统一的基础服务架构上,团队成员的开发工作模式一致,并且沟通语言都是基于此,一定程度上会提升协作效率和沟通效率。
同时,开发人员更容易理解非自己主导项目的脉络主线,可以极大地降低工作内容调整和交接的复杂度。从另一个角度提升了协作、沟通效率。
在统一的基础服务架构下,团队不再需要关心一些通用的细节,只是按需调用 / 复用通用组件,将主要的精力用在解决问题的核心算法 / 模型上,这样一来,加速了团队的技术积累,快速地推进业务的创新。
这张图可以简单的展示知乎基础 AI 架构的体系。
我们的统一框架取名叫 zai,本质上是一个工作流水线。其中的每个部件都是可定制的。workflow 分为三大类:
- base workflow,通常只包含一种推断服务或预测服务。
- series workflow ,其可以串联多个不同的 base workflow,形成一个更复杂的服务链,比如关键词服务,需要前序依赖分词服务。
- parallel workflow ,其可以并联多种 series workflow,形成相对比较复杂的网络,比如监听内容创建 kafka topic,并分别进行多种预测处理。
在这个框架中,我们选择 proto buffer 来进行数据 schema 的定义,满足速率快和存储小的需求。
zai-serving 是预测 / 推荐模块,加载 zai-model 模块训练出来的模型来进行推断服务。模型可以支持传统模型和 NN 模型。其中 NN 模型基于 tensorflow estimator 做了改造和封装,这样具备以下优点:
- 数据管道和模型分离。
- 保留足够的模型灵活度,具有模型自定义的自由和模型相关超参调整的自由。
- 封装了训练、预测、评估、模型输出;只需要关心模型本身。
基础 AI 架构的主要应用场景,一般是各种离线的数据处理场景。在典型的线上推荐场景中,我们也正在形成统一推荐框架。
统一推荐 AI 架构
当越来越多的业务都需要用到推荐服务时,我们开始了统一推荐框架的工作:我们期望通过统一 Ranking 框架,将推荐系统全局排序阶段的技术统一,降低开发和维护成本,提高效率。
知乎的统一推荐框架包括以下模块:
- 统一的完备的数据 schema,打通各业务线的数据,减少重复特征数据的落地成本,并成为统一推荐框架的标准输入。
- 统一的特征落盘服务,各业务线可根据业务特点,灵活填充 schema 中的特征字段,减少在特征落盘和训练数据管理部分的开发工作。特定业务还可以低成本的实现跨部门数据复用,打通不同部门之间的数据协同作用。
- 统一的训练数据流水线。
- 统一的特征工程框架。
- 统一的训练代码库。有利于模型结构复用,兼容离线训练和 online learning 训练。
- 统一的线上预测服务。支持 tensorflow 和 xgboost 的模型;支持模型的自动加载和更新;提供通用的特征、预测分数监控。支持 CPU 或 GPU 部署。优化公共特征计算。
我重点讲一下其中的几个模块。
第一个是特征引擎。
特征数据处理,是要把结构化的特征数据(如用户画像,内容画像等)转换成向量化的训练数据。我们的特征引擎具备以下功能:
- 特征工程配置化:管理使用哪些特征;增删特征无需改代码。避免了离线数据处理和线上预测服务代码不一致的情况。
- 特征工程模块化:我们把对特征数据的操作抽象成一个个操作子 (operator)。比如:Echo, OneHot 等。规范了 operator 的输入输出;每个 operator 可以处理不同的特征数据;大部分 operator 和具体的业务无关,代码可复用性大大增强。每个 operator 必须有严格的单元测试,保证了特征工程代码质量。
- 结构化数据字段获取动态加速,有效的提升效率。
- 自定义向量化特征数据格式:避免了 parse protobuf 的序列化、反序列化 cpu 开销,比 tensorflow 的 tf record 快很多,典型场景有 10 倍的性能差异。
第二个是特征落盘服务。
为了对特征覆盖率等指标进行监控,并让落地的数据在多个业务之间低成本复用,特征在落地之前需要经过统一落盘处理。落盘服务提供的主要功能有:
- 流式特征覆盖率统计监控,特征分布统计。
- 样本数据分流。大的样本数据尽量落成一份,小的特殊业务可以进行灵活的分流。
- 跨业务的进行特征补全。
未来,知乎的统一推荐框架将在三个方面进行完善和升级:
- 一站式配置管理、数据流管理、特征监控、指标监控。
- 通用化 online learning,让更多业务可以直接用在线学习的优势。
- AutoML,降低业务使用机器学习模型的门槛。
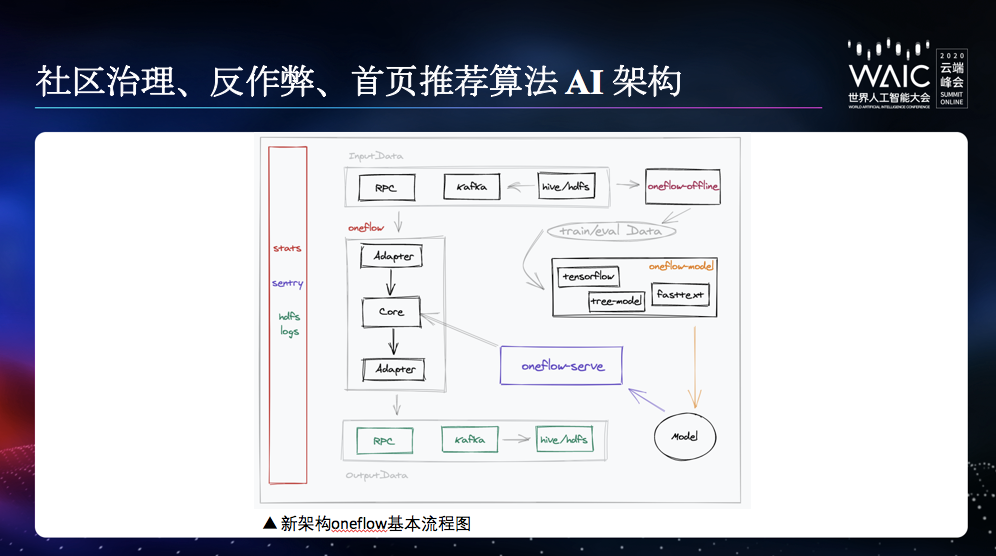
社区治理、反作弊及多媒体 AI 架构
除了统一推荐,知乎还有一个很特殊的场景,就是社区治理。除了垃圾信息、有害信息的处理,一些对社区内容建设和人们的需求没帮助的信息,也在知乎的治理范围内,比如答非所问、阴阳怪气等等。这个场景沉淀出来的基础框架,和前面提到的 zai 框架是比较相似的,但是整个框架针对图片、视频等多媒体内容,做了很多特化的优化处理,比如通用的缓存转码之类的。具体细节在这里就不赘述了。
机器学习架构—Jeeves 机器学习平台
除了直接面向业务应用场景的三个框架之外,我们还构建了机器学习平台 Jeeves,用于帮助算法工程师快速构建、训练和部署机器学习任务。Jeeves 将算法工程师从繁重的部署和配置工作中解放出来,专注于高质量模型的开发。
随着机器学习对 GPU 资源的需求快速增加,仅通过算法工程师自行管理、调度,不仅增加了业务部门管理成本,也造成了 GPU 等计算资源一定程度的浪费。具体包括以下几点:

- 训练前部署难。算法工程师需投入大量精力进行运行环境的配置和资源调配,不便于工程师专注于模型优化和调参。
- 资源配置优化难。算法工程师难以判断机器学习任务的性能瓶颈在哪种资源上(如 CPU、GPU、内存等),不便于全局优化资源调配。
- 单机训练瓶颈。纵向扩展成本高、提升小。机器学习需要快速迭代试错,性能瓶颈制约了其最终产出的质量和速度。
Jeeves 将 Tensorflow 容器化,通过容器进行训练资源的调度和管理,并为算法工程师提供方便的资源申请和释放流程。具体来说,Jeeves 提供:
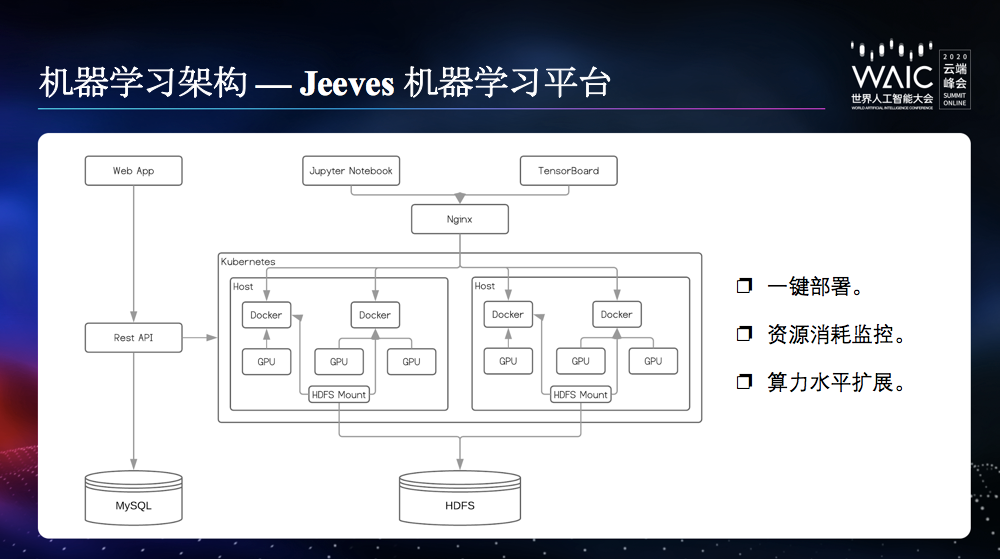
- 一键部署能力。算法工程师只需要申请资源、载入训练数据和代码,即可一键部署环境并开展工作。
- 资源消耗监控。监控资源在每个任务的消耗情况,便于识别瓶颈所在,针对性的进行性能优化和资源调配。
- 算力水平扩展。支持分布式机器学习,支持算力的快速扩展。
下图是 Jeeves 及其学习平台架构。Jeeves 通过容器管理 GPU 集群的资源,底层使用 Docker 来隔离 GPU 资源,并通过 Kubernetes 对 Docker 容器进行调度。并提供训练数据挂载,日志和模型的持久化的功能。同时 Jeeves 还会监测空闲资源并保证其及时回收,提高资源利用效率。
功能层面,Jeeves 主要提供两类功能:一种是「笔记本」,用于在线交互式试验训练代码;另一种是「项目」,用于创建单机或分布式训练。
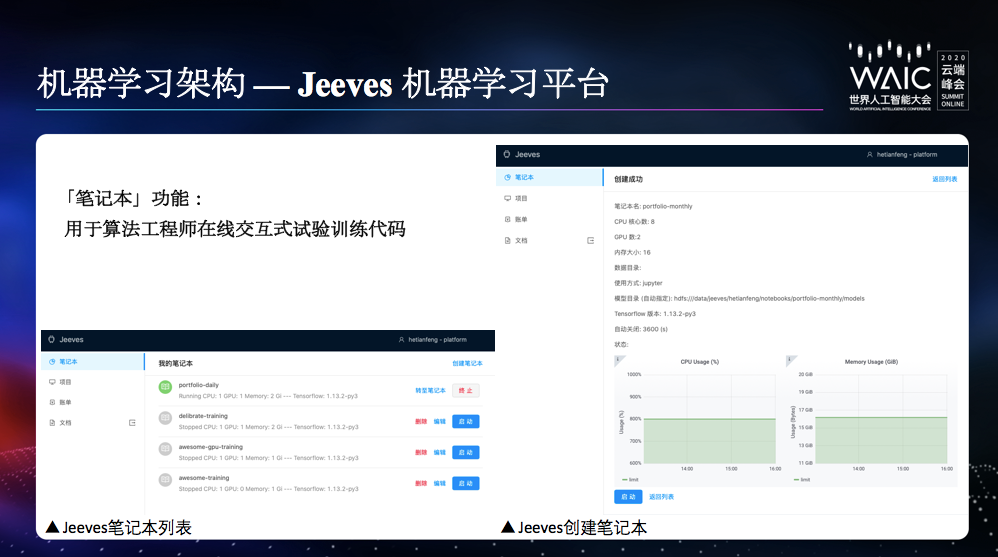
笔记本为算法工程师提供交互式体验和数据科学可视化的工具,用户可以通过浏览器快速迭代优化训练代码。对于不习惯使用浏览器或者不方便使用浏览器的用户,Jeeves 还提供了 ssh notebook 的功能。
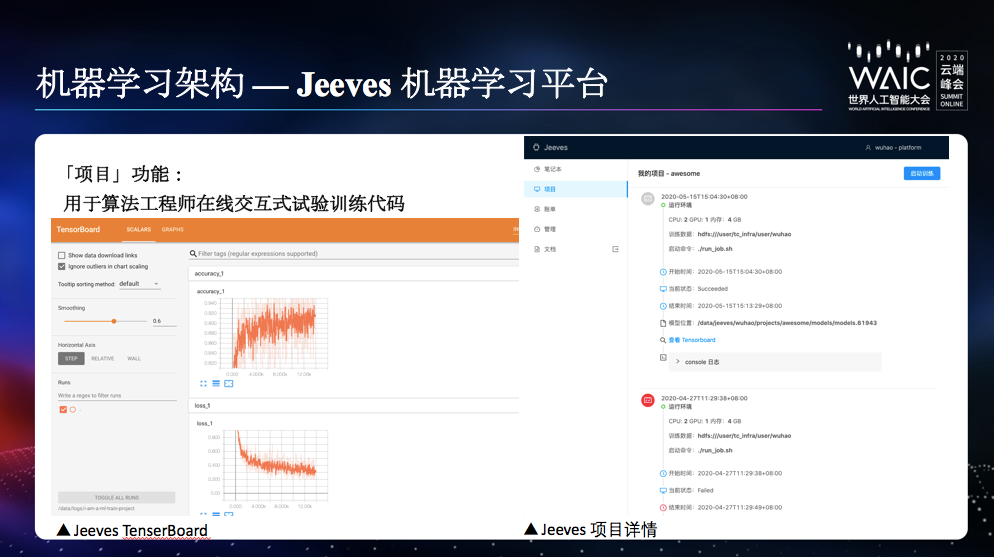
项目分为单机训练和分布式训练两类。单机训练使用一台独立服务器执行训练任务;而分布式训练根据用户申请的资源用量,将任务合理拆分后,交由对应集群执行。项目启动后,Jeeves 会提供 TensorBoard,辅助用户掌握训练过程。
总结
以上是知乎最近在 AI 应用实践中逐步沉淀出来的一些基础框架和提效平台。AI 应用本质上是能够对海量数据进行高效应用的前沿计算机算法系统,因此,过去常规计算机系统在数据规模和业务请求量增大到一定程度后,会遇到的各种问题,AI 应用也同样会遇到。如果解决这些问题,就需要有良好的架构设计,否则再好的数据和模型,也都会受制于系统的计算能力和吞吐能力,不能发挥数据和模型完整的表达能力。所以,在工业界真实的生产环境中,AI 应用必须同时兼顾数据、算法和架构三者的投入。作个不太适当的比喻,这三者的关系就好像食材、菜谱和厨具,要想把 AI 应用的用户体验这道菜做的色香味俱全,三样东西每样都要做好、做足、做精。
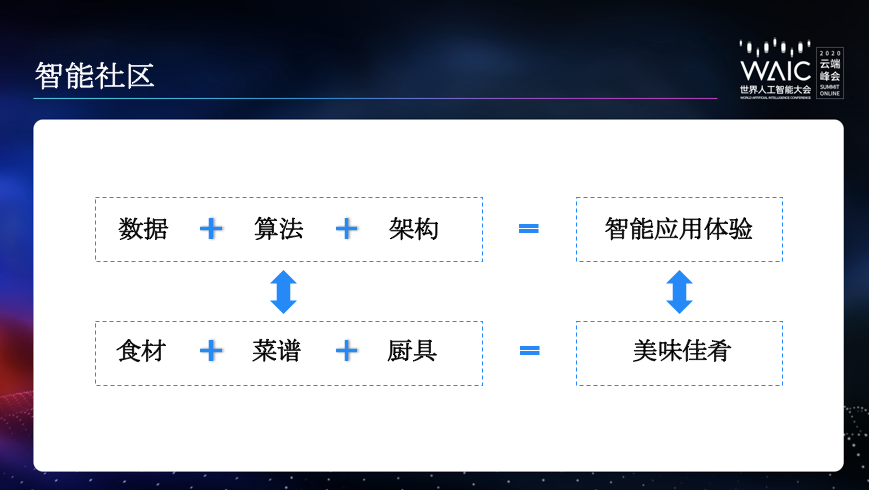
通过这些框架的落地和应用,我们也希望知乎这个内容社区,能够在更多的产品细节上,轻松使用各种 AI 技术,成为一个人与技术、人与机器、人文与技术有效融合「智能社区」。
最后,打个广告,欢迎更多对 AI 技术有兴趣和热情的同学加入我们,加入知乎,一起做些更有趣、更有挑战性的工作。我的分享就到这里,谢谢大家。
本文为机器之心报道,转载请联系本公众号获得授权。