对于频繁使用的查找表,希望 ASL = 0
记录在表中位置和其关键字之间存在一种确定的关系
HASH
定义
- 根据设定的哈希函数 H(key) 和所选中的处理冲突的方法,将一组关键字映象到一个有限的、地址连续的地址集 (区间) 上,并以关键字在地址集中的“象”作为相应记录在表中的存储位置,如此构造所得的查找表称之为“哈希表”
HASH函数的构造
- 构造原则
– 函数本身便于计算
– 计算出来的地址分布均匀,即对任一关键字k,f(k) 对应不同地址的概率相等,目的是尽可能减少冲突
直接定址法
- 哈希函数为关键字的线性函数
– H(key) = key
– H(key) = a * key + b - 此法仅适合于:
地址集合的大小 = = 关键字集合的大小 - 优点:以关键码key的某个线性函数值为哈希地址,不会产生冲突
- 缺点:要占用连续地址空间,空间效率低
数字分析法
- 假设关键字集合中的每个关键字都是由 s 位数字组成 (u1, u2, …, us),分析关键字集中的全体, 并从中提取分布均匀的若干位或它们的组合作为地址
- 此方法仅适合于:
能预先估计出全体关键字的每一位上各种数字出现的频度
平方取中法
- 以关键字的平方值的中间几位作为存储地址。求“关键字的平方值” 的目的是“扩大差别” ,同时平方值的中间各位又能受到整个关键字中各位的影响
- 此方法适合于:
关键字中的每一位都有某些数字重复出现频度很高的现象
折叠法
- 将关键字分割成若干部分,然后取它们的叠加和为哈希地址。有两种叠加处理的方法:移位叠加和间界叠加
- 此方法适合于:
关键字的数字位数特别多
除留余数法
- Hash(key)=key mod p (p是一个整数)
– p≤m (表长)
– p 应为小于等于 m 的最大素数为什么要对 p 加限制?- 给定一组关键字为: 12, 39, 18, 24, 33, 21若取 p=9, 则他们对应的哈希函数值将为:
3, 3, 0, 6, 6, 3
可见,若 p 中含质因子 3, 则所有含质因子 3 的关键字均映射到“3 的倍数”的地址上,从而增加了“冲突”的可能
随机数法
- H(key) = Random(key) (Random 为伪随机函数)
- 此方法用于对长度不等的关键字构造哈希函数
考虑因素
- 执行速度(即计算哈希函数所需时间)
- 关键字的长度
- 哈希表的大小
- 关键字的分布情况
- 查找频率
采用何种构造哈希函数的方法取决于建表的关键字集合的情况
原则是使产生冲突的可能性降到尽可能地小
处理冲突的方法
1. 开放定址法
基本思想
- 有冲突时就去寻找下一个空的哈希地址,只要哈希表足够大,空的哈希地址总能找到,并将数据元素存入线性探测法
- Hi=(Hash(key)+di) mod m ( 1≤i < m )
其中:m为哈希表长度
di 为增量序列 1,2,…m-1,且di=i
一旦冲突,就找下一个空地址存入
- 优点:只要哈希表未被填满,保证能找到一个空地址单元存放有冲突的元素
- 缺点:能使第i个哈希地址的同义词存入第i+1个地址,这样本应存入第i+1个哈希地址的元素变成了第i+2个哈希地址的同义词,……,产生“聚集”现象,降低查找效率
二次探测法
di = 12, -12, 22, -22, …±k2
伪随机探测法
Hi=(Hash(key)+di) mod m ( 1≤i < m )
其中:m为哈希表长度
di 为随机数开放定址法建立哈希表步骤
- 取数据元素的关键字key,计算其哈希函数值(地址)。若该地址对应的存储 空间还没有被占用,则将该元素存入;否则执行step2解决冲突开放定址哈希表的存储结构/* ————- 开放定址哈希表的存储结构 ————- */
int hashsize[] = {997, …};
typedef struct{
ElemType* elem;
int count; // 当前数据元素个数
int sizeindex; // hashsize[sizeindex]为当前容量
} HashTable;#define SUCCESS 1
#define UNSUCCESS 0
#define DUPLICATE -1Status SearchHash(HashTable H, KeyType K, int &p, int &c){
// 在开放定址哈希表H中查找关键码为K的记录
p = Hash(K); // 求得哈希地址
while(H.elem[p].key != NULLKEY && !EQ(K, H.elem[p].key))
collisiion(p, ++c); // 求得下一探测地址p
if(EQ(K, H.elem[p].key)) return SUCCESS; // 查找成功,返回待查数据元素位置 p
else return UNSUCCESS; // 查找不成功
}2. 再HASH法undefined - 根据选择的冲突处理方法,计算关键字key的下一个存储地址。若下一个存储地址仍被占用,则继续执行step2,直到找 到能用的存储地址为止
- H2(key) 是另设定的一个哈希函数,它的函数值应和 m 互质

在这里插入图片描述
3. 链地址法
基本思想
- 相同哈希地址的记录链成一单链表,m个哈希地址就设m个单链表,然后用用一个数组将m个单链表的表头指针存储起来,形成一个动态的结构

在这里插入图片描述
优点:
- 非同义词不会冲突,无“聚集”现象
- 链表上结点空间动态申请,更适合于表长不确定的情况
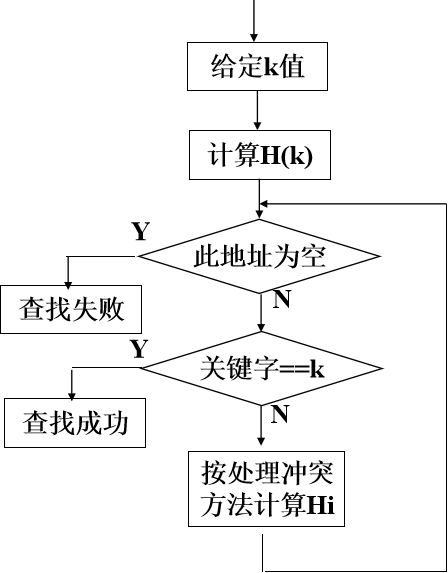
哈希表的查找
对于给定值 K,计算哈希地址 i = H(K)
- 若 ri = NULL 则查找不成功
- 若 ri.key = K 则查找成功, 否则 “求下一地址 Hi” ,直至rHi = NULL (查找不成功) 或rHi.key = K (查找成功) 为止
案例v01
- 线性探测法解决冲突

在这里插入图片描述
案例v02
- 链地址法处理冲突

在这里插入图片描述
哈希表查找的分析
从查找过程得知,哈希表查找的平均查找长度实际上并不等于零
决定哈希表查找的ASL的因素
- 选用的哈希函数
- 选用的处理冲突的方法
- 哈希表饱和的程度,装载因子 α=n/m 值的大小(n—记录数,m—表的长度)α 越大,表中记录数越多,说明表装得越满,发生冲突的可能性就越大,查找时比较次数就越多

在这里插入图片描述
- 对哈希表技术具有很好的平均性能,优于一些传统的技术
- 链地址法优于开地址法
- 除留余数法作哈希函数优于其它类型函数
哈希表应用举例
编译器对标识符的管理多是采用哈希表
- 构造哈希函数的方法
– 将标识符中的每个字符转换为一个非负整数
– 将得到的各个整数组合成一个整数(可以将第一个、中间的和最后一个字符值加在一起,也可以将所有字符的值加起来)
– 将结果数调整到0~M-1范围内,可以利用取模的方法,Ki%M(M为素数)