什么是AES
AES是对称加密算法的一种,全称是ADVANCED ENCRYPTION STANDARD。
高级加密标准 (AES) 指定了 FIPS 批准的 可用于保护电子数据的密码算法。AES 算法是一种对称分组密码,可以对信息进行加密(加密)和解密(解密)。加密将数据转换为难以理解的形式,称为密文;解密密文会将数据转换回其原始形式,称为明文。
关于AES标准的详细论述,可以参考《Federal Information Processing Standards Publication 197》,这里不再赘述。
AES支持的模式
AES支持以下加密模式:
1. ECB模式(The Electronic Codebook Mode)
2. CBC模式(The Cipher Block Chaining Mode)
3. CTR模式(The Counter Mode)
4. GCM模式(The Galois/Counter Mode)
5. CFB模式(The Cipher Feedback Mode)
6. OFB模式(The Output Feedback Mode)AES的加密模式根据加密方式的不同,简单分为块加密模式与流加密模式两种。
块加密模式最为常见同时在工程化中使用最为普遍的是CBC模式。
流加密模式最具代表性的是GCM模式。
块加密与数据填充
明文数据的填充是块加密模式最重要的特点之一。
为什么需要填充呢?这有个很重要的原因是因为,加密库(或者说加密算法)本身,是无法预料用户输入的明文长度究竟是多少的!
对于AES来说,ta只知道自己是按照16字节进行分组加密的,这里的分组加密说的更严谨点,应该是,对明文按照16个字节进行分组进行加密(这里我们暂时不讨论每种模式下的区别)。
如果输入的明文长度不是16字节整数倍,这个时候就需要强行将明文进行填充对齐,使其能够满足分组规则。
比较常见的几种填充法则如下:
- NoPadding:顾名思义,就是不填充。缺点就是只能加密长为BlockSize倍数的信息,一般不会使用。
- ZerosPadding:全部填充0x00,无论缺多少全部填充0x00,已经是BlockSize的倍数仍要填充,一般工程上不使用这种方式。
- PKCS#5:缺几个字节就填几个字节,每个字节的值为缺的字节数;在AES加密当中严格来说是不能使用PKCS#5的,因为AES的块大小是16bytes而PKCS#5只能用于8bytes。
- PKCS#7:缺几个字节就填几个字节,每个字节的值为缺的字节数;当长度不对齐时,将数据填充到满足分组的长度;当长度刚好对齐时,在原始数据末尾新增一个填充块;OpenSSL在AES加密中默认使用PKCS#7。
- ISO 10126:最后一个字节的值是需要填充的字节数(需要填充的字节数包括了最后一字节),其他全部填随机数。
- ANSI X9.23:跟ISO 10126很像,只不过ANSI X9.23其他字节填的都是0而不是随机数。
PKCS#7填充效果:
def padding_check(self, origin: str, block_size: int):
"""
假设BlockSize为128即16个字节,则:
对于原文长度不足16个字节的,按照16字节(128比特)的BlockSize进行填充
"""
padder = padding.PKCS7(block_size).padder()
ret = padder.update(origin.encode('utf-8'))
ret += padder.finalize()
print("origin=", list(origin),
"after padding=", list(ret))
""" 验证填充完成后的字节数是否符合预期 """
self.assertEqual(len(ret) % get_bytes_len(block_size), 0)
""" 填充值同时也是填充的字节长度 """
padding_value = get_padding_value(
get_bytes_len(block_size), len(origin))
""" 填充长度为 padding_value 个字节,每个字节的值应该都是 padding_value """
for i in range(1, padding_value + 1):
self.assertEqual(int(ret[0 - i]), int(padding_value))本文后续内容我们默认使用PKCS#7进行冗余填充。
不安全的块加密:ECB
ECB模式是不安全的,不建议在工程实践中使用这种模式。
def test_ecb_cipher(self):
origin_1 = "aaaaaaaaaaaaaaaa"
origin_2 = "bbbbbbbbbbbbbbbb"
origin_3 = (origin_1 + origin_2)
key = "1234567890123456".encode('utf-8')
aes_obj = aes_encryption.aes_encryption("ecb", key)
print("Current AES Mode:", aes_obj.current_mode)
cipher_1, cipher_1_len = aes_obj.encrypt(origin_1.encode('utf-8'))
cipher_2, cipher_2_len = aes_obj.encrypt(origin_2.encode('utf-8'))
cipher_3, cipher_3_len = aes_obj.encrypt(origin_3.encode('utf-8'))
print("cipher_1:{}".format(list(cipher_1)))
print("cipher_2:{}".format(list(cipher_2)))
print("cipher_3:{}".format(list(cipher_3)))
""" ECB模式下的密文与明文一一对应,不安全 """
self.assertEqual(cipher_1_len % 16, 0)
self.assertEqual(cipher_2_len % 16, 0)
self.assertEqual(cipher_3_len % 16, 0)
self.assertEqual(
cipher_1[:cipher_1_len - 16] + cipher_2[:cipher_2_len - 16], cipher_3[:cipher_3_len - 16])
self.assertEqual(len(aes_obj.key_value) % 16, 0)
self.assertLessEqual(len(aes_obj.key_value), 32)当我们使用ECB模式分别对明文:aaaaaaaaaaaaaaaa、bbbbbbbbbbbbbbbb以及aaaaaaaaaaaaaaaabbbbbbbbbbbbbbbb做加密时,我们稍微观察就会发现,密文其实是重复出现的。
ECB模式有一个显著的安全问题:如果使用相同的密钥,那么相同的明文块就会生成相同的密文块,不能很好的隐藏数据模式。
细心点的朋友可能已经发现,重复出现的数据是三部分,那么为什么是三部分呢?
这个作为思考题留给大家,欢迎在评论区交流。
经典块加密模式:CBC
对于块加密模式来说,始终都有:密文长度与填充后的明文长度等长!!!
def test_aes_cbc_encryption(self):
origin = os.urandom(random.randint(17, 256))
key = os.urandom(32)
iv = os.urandom(16)
aes_obj = aes_encryption.aes_encryption("cbc", key, iv)
print("Current AES Mode:", aes_obj.current_mode)
cipher, cipher_len = aes_obj.encrypt(origin)
plain, plain_len = aes_obj.decrypt(cipher)
self.assertEqual(plain, origin)
self.assertEqual(len(origin), plain_len)
self.assertGreaterEqual(cipher_len, len(origin))
print("cipher_len:", cipher_len)
print("origin_len:", len(origin))
print("len(origin) % 16 = ", len(origin) % 16)
"""
假如原始数据长度等于 BlockSize * n,
则使用 NoPadding 时加密后数据长度等于 BlockSize * n,其它情况下加密数据长度等于 BlockSize * (n+1)。
假如原始数据长度等于 BlockSize*n+m [其中 m 小于BlockSize],
除了 NoPadding 填充之外的任何方式,加密数据长度都等于 BlockSize*(n+1);
"""
if len(origin) % 16 == 0:
self.assertEqual(cipher_len, len(origin))
else:
self.assertEqual(cipher_len, (len(origin) // 16 + 1) * 16)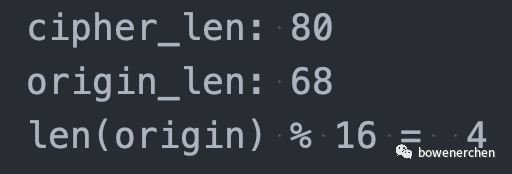
CBC模式作为工程上使用最广泛的一种加密模式,平时在使用它时,我们的密钥长度、IV长度、分组长度与加密轮转次数的关系如下图:

在 CBC 模式加密中,第一个输入块是通过将明文的第一个块与 IV 异或形成的。
前向密码函数应用于第一个输入块,并且结果输出块是密文的第一个块。该输出块还与第二个明文数据块异或以产生第二个输入块,并应用前向密码函数以产生第二个输出块。
该输出块,即第二个密文块,与下一个明文块异或以形成下一个输入块。每个连续的明文块与前一个输出/密文块进行异或运算以产生新的输入块。
前向密码函数应用于每个输入块以产生密文块。
在 CBC 解密中,逆密码函数应用于第一个密文块,得到的输出块与初始化向量进行异或以恢复第一个明文块。
逆密码函数也应用于第二个密文块,得到的输出块与第一个密文块异或以恢复第二个明文块。
经典的AES-CBC逻辑抽象图:
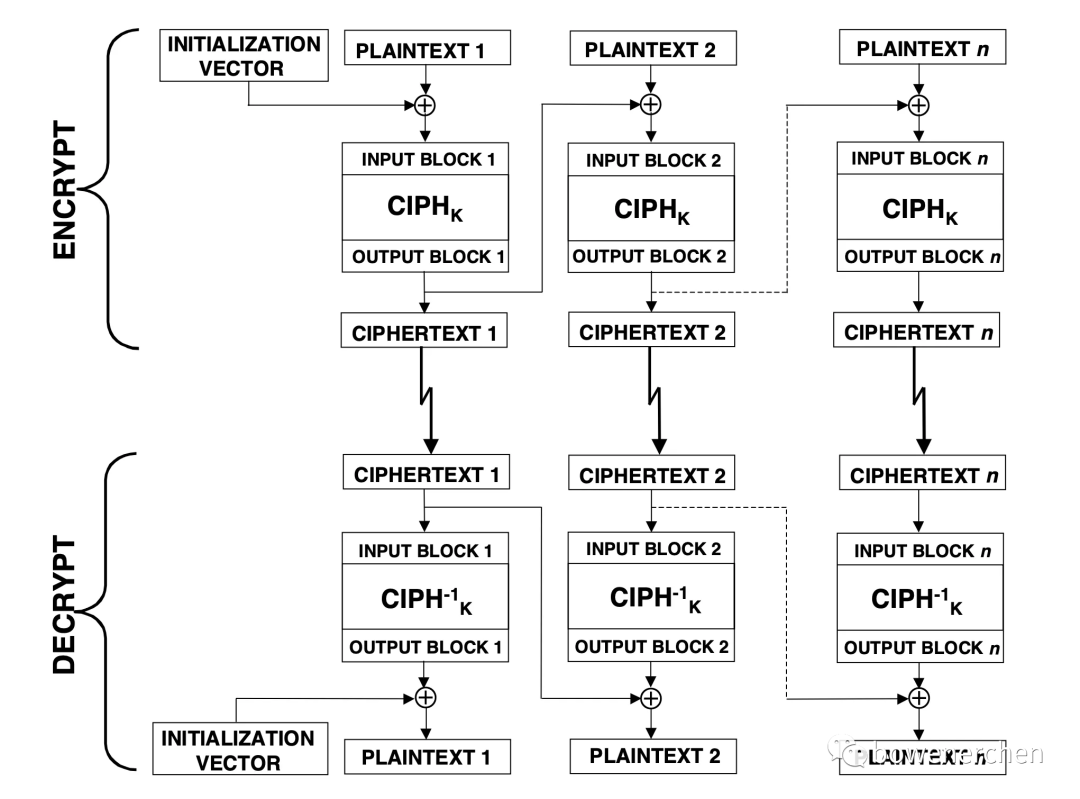
通常,要恢复任何明文块(第一个除外),将逆密码函数应用于相应的密文块,并将结果块与前一个密文块进行异或运算。
在 CBC 加密中,每个前向密码操作(第一个除外)的输入块取决于前一个前向密码操作的结果,因此前向密码操作不能并行执行。
CBC模式的链式反应指的是加密的过程,因为当IV改变,加密过程中的所有密文block都会改变;
而解密的时候,IV只会对第一个明文block有影响。
def test_aes_cbc_decrypt_by_wrong_iv(self):
"""
CBC模式的链式反应一般指的是加密的过程,因为当IV改变,加密过程中的所有密文block都会改变
而解密的时候IV只会对第一个明文block有影响
"""
# 64字节长度的明文
origin_plain = os.urandom(64)
print("origin_plain[0:16]:{}".format(list(origin_plain[0:16])))
print("origin_plain[16:32]:{}".format(list(origin_plain[16:32])))
print("origin_plain[32:48]:{}".format(list(origin_plain[32:48])))
print("origin_plain[48:64]:{}".format(list(origin_plain[48:64])))
# 32字节长度的key
key = os.urandom(32)
# print("key:{}".format(list(key)))
# 16字节长度的iv
iv = os.urandom(16)
print("correct iv:{}".format(list(iv)))
aes_obj = aes_encryption.aes_encryption("cbc", key, iv)
cipher, cipher_len = aes_obj.encrypt(origin_plain)
# 使用正确的key 和 iv进行解密
plain, plain_len = aes_obj.decrypt(cipher)
self.assertEqual(plain, origin_plain)
self.assertEqual(len(origin_plain), plain_len)
self.assertGreaterEqual(cipher_len, len(origin_plain))
# 将iv设置为错误的值
aes_obj.iv_value = os.urandom(16)
self.assertNotEqual(iv, aes_obj.iv_value)
print("wrong iv:{}".format(list(aes_obj.iv_value)))
wrong_plain, wrong_plain_len = aes_obj.decrypt(cipher)
print("wrong_plain[0:16]:{}".format(list(wrong_plain[0:16])))
print("wrong_plain[16:32]:{}".format(list(wrong_plain[16:32])))
print("wrong_plain[32:48]:{}".format(list(wrong_plain[32:48])))
print("wrong_plain[48:64]:{}".format(list(wrong_plain[48:64])))
# 即使使用错误的iv进行解密,但是得到的长度还是正确的,只是解密出来的内容会有不同
self.assertNotEqual(wrong_plain, origin_plain)
self.assertNotEqual(wrong_plain, plain)
self.assertEqual(len(origin_plain), wrong_plain_len)
# 解密的时候,错误的iv只影响明文块的第一个16字节block
self.assertNotEqual(wrong_plain[0:16], origin_plain[0:16])
self.assertEqual(wrong_plain[16:], origin_plain[16:])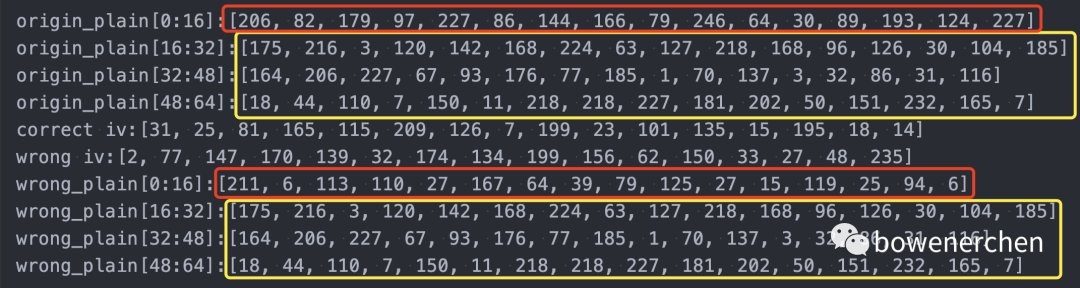
不同于块加密模式的流加密模式:CTR与GCM
CTR模式
在 CTR 加密中,在每个计数器块上调用前向密码函数,结果输出块与相应的明文块异或以产生密文块。对于最后一个块,它可能是u位的部分块,最后一个输出块的最高有效u位用于异或运算;最后一个输出块的剩余 b-u 位被丢弃。
在 CTR 解密中,对每个计数器块调用前向密码函数,将得到的输出块与相应的密文块异或以恢复明文块。对于最后一个块,它可能是u位的部分块,最后一个输出块的最高有效u位用于异或运算;最后一个输出块的剩余 b-u 位被丢弃。
在CTR加密和CTR解密中,前向密码功能可以并行执行;类似地,如果可以确定对应的计数器块,则可以独立于其他明文块恢复对应于任何特定密文块的明文块。此外,可以在明文或密文数据可用之前将前向密码函数应用于计数器。
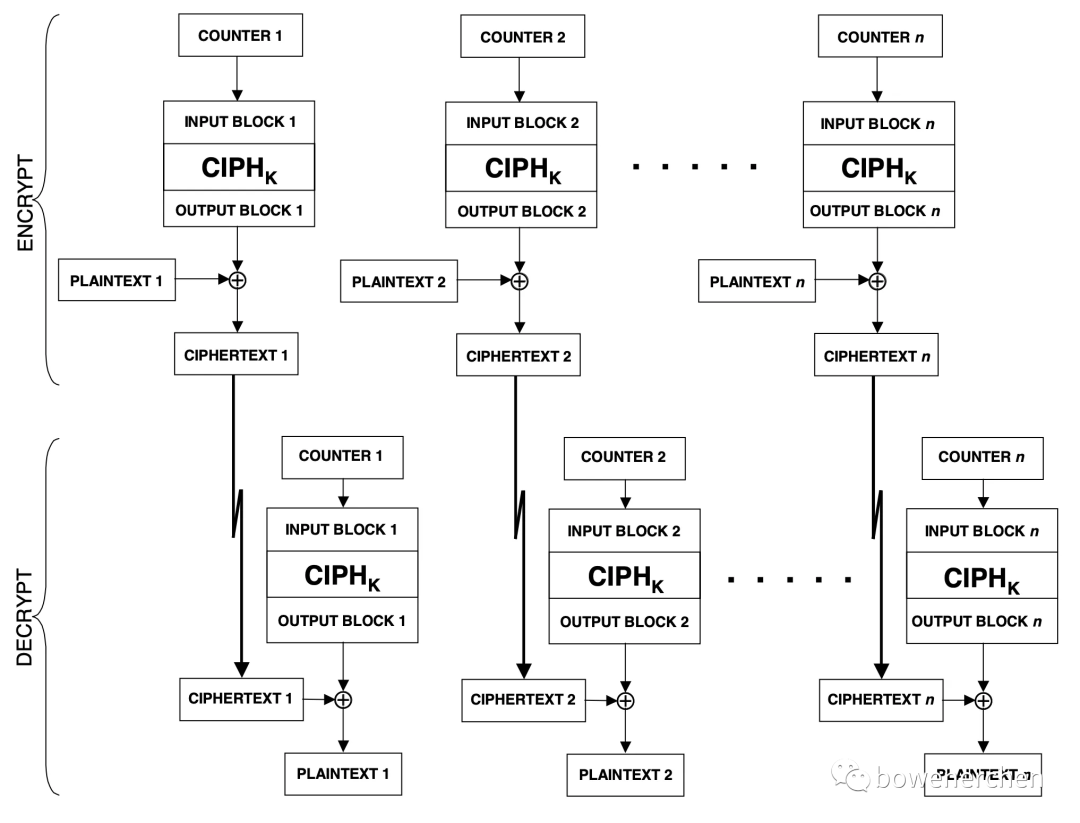
CTR模式有很多优点:易于理解,效率高,不需要padding,支持并行化,随机访问,以及只需要加密函数等等。
但是,CTR也有一些显而易见的缺点:
无法保证消息的完整性:
缺乏消息身份验证,攻击者很容易对截获的加密消息进行比特翻转,再重放,且无需对其进行解密。
而因为CTR模式的延展性,一个比特的反转就会带来毁灭性的结果。
计数器块重用导致明文泄露:
如果计数器块(nonce)被重用,它可能会导致泄漏明文;
特别是CTR模式加密需要唯一的随机数输入,绝对不能将其重复用于使用同一密钥加密的两条不同的消息,所以随机数生成方法尤为重要。
密文长度已知(可以通过padding对原文的长度进行隐藏):
因为CTR模式不需要padding,所以其加密后的密文长度是可以知道的。
尽管在许多加密方法中,消息长度并不被视作秘密(secert),但由于对称加密的特性,所以可以获得对应的明文长度,
从而出现明文高位泄露的风险。GCM模式
GCM可以提供对消息的加密和完整性校验,另外,它还可以提供附加消息的完整性校验。在实际应用场景中,有些信息是我们不需要保密,但信息的接收者需要确认它的真实性的,例如源IP,源端口,目的IP,IV,等等。
因此,我们可以将这一部分作为附加消息加入到MAC值的计算当中。
GCM模式是一种很经典的AEAD(Authenticated Encryption with Associated Data)。
AEAD是一种同时具备保密性,完整性和可认证性的加密形式。
AEAD 产生的原因很简单,单纯的对称加密算法,其解密步骤是无法确认密钥是否正确的,也就是说,加密后的数据可以用任何密钥执行解密运算,得到一组疑似原始数据,而不知道密钥是否是正确的,也不知道解密出来的原始数据是否正确,因此,需要在单纯的加密算法之上,加上一层验证手段,来确认解密步骤是否正确。
常见的 AEAD 算法有:
AES-128-GCM
AES-192-GCM
AES-256-GCM
ChaCha20-IETF-Poly1305
ChaCha20-IETF-Poly1305具备 AES 加速的 CPU(桌面,服务器)上,建议使用 AES-XXX-GCM 系列,移动设备建议使用 ChaCha20-IETF-Poly1305 系列。
CBC与GCM的对比
AES-GCM可以并行加密解密,AES-CBC的模式决定了它只能串行地进行加密。
因为加密是耗时较久的步骤,且加密的方式是相同的,所以并行地实现AES-GCM算法的时候,其效率是高于AES-CBC的。
AES-GCM提供了GMAC信息校验码,用以校验密文的完整性。AES-CBC没有,无法有效地校验密文的完整性;
AES-GCM是流加密的模式,不需要对明文进行填充。AES-CBC是块加密的模式,需要对明文进行填充(AES-GCM中进行AES加密的是counter,AES-CBC中进行AES加密的是明文块)。
由于AES-CBC中必须要用到padding,导致最后一个明文块与其他密文块不同,因此可能会受到padding Oracle attacks,从而可以直接通过初始向量IV和密码,即可得到明文。
这一部分会在本系列的其他文章中详细描述,敬请期待!