简介
由于各种姿势,照明和遮挡,在不受限制的环境中进行人脸检测和对齐具有挑战性。 最近的研究表明,深度学习方法可以在这两项任务上取得令人印象深刻的性能。 在本文中,我们提出了一个深层级联的多任务框架,该框架利用它们之间的固有关联性来提高其性能。 特别是,我们的框架采用了三级精心设计的深层卷积网络的级联结构,这些网络以粗糙到精细的方式预测面部和界标的位置。 此外,在学习过程中,我们提出了一种新的在线硬样本挖掘策略,该策略可以自动提高性能,而无需手动选择样本。 我们的方法在具有挑战性的FDDB和WIDER FACE基准用于面部检测,以及AFLW基准用于面部对准方面,具有比最新技术更高的准确性,同时保持了实时性能。
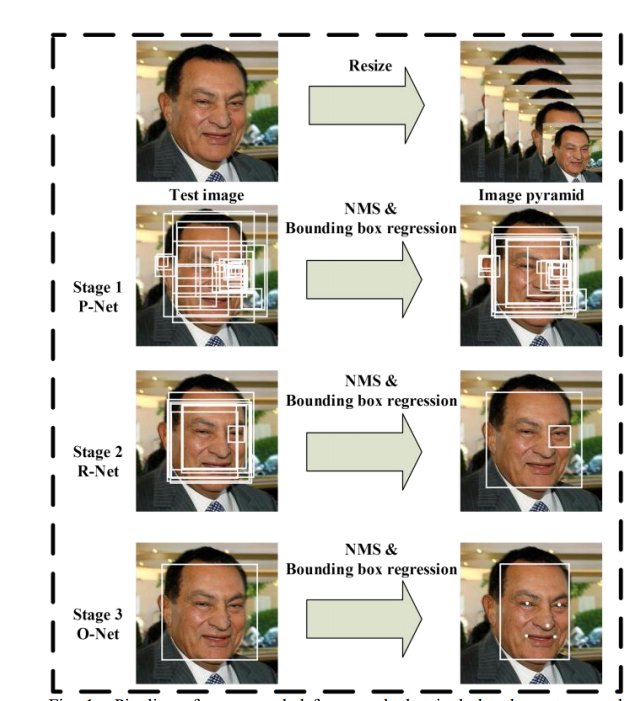
首先对test图片不断进行Resize,得到图片金字塔。按照resize_factor(如0.70,这个具体根据数据集人脸大小分布来确定,基本确定在0.70-0.80之间会比较合适,设的比较大,容易延长推理时间,小了容易漏掉一些中小型人脸)对test图片进行resize,直到大等于Pnet要求的12*12大小。这样子你会得到原图、原图*resize_factor、原图*resize_factor^2…、原图*resize_factor^n(注,最后一个的图片大小会大等于12)这些不同大小的图片,堆叠起来的话像是金字塔,简单称为图片金字塔。注意,这些图像都是要一幅幅输入到Pnet中去得到候选的。
P-NET
图片金字塔输入Pnet,得到大量的候选(candidate)。根据上述步骤1得到的图片金字塔,将所有图片输入到Pnet,得到输出map形状是(m, n, 16)。根据分类得分,筛选掉一大部分的候选,再根据得到的4个偏移量对bbox进行校准后得到bbox的左上右下的坐标(根据偏移量矫正先埋个坑,描述训练阶段的时候补),对这些候选根据IOU值再进行非极大值抑制(NMS)筛选掉一大部分候选。详细的说就是根据分类得分从大到小排,得到(num_left, 4)的张量,即num_left个bbox的左上、右下绝对坐标。每次以队列里最大分数值的bbox坐标和剩余坐标求出iou,干掉iou大于0.6(阈值是提前设置的)的框,并把这个最大分数值移到最终结果。重复这个操作,会干掉很多有大量overlap的bbox,最终得到(num_left_after_nms, 16)个候选,这些候选需要根据bbox坐标去原图截出图片后,resize为24*24输入到Rnet。
R-NET
经过Pnet筛选出来的候选图片,经过Rnet进行精调。根据Pnet输出的坐标,去原图上截取出图片(截取图片有个细节是需要截取bbox最大边长的正方形,这是为了保障resize的时候不产生形变和保留更多的人脸框周围细节),resize为24*24,输入到Rnet,进行精调。Rnet仍旧会输出二分类one-hot2个输出、bbox的坐标偏移量4个输出、landmark10个输出,根据二分类得分干掉大部分不是人脸的候选、对截图的bbox进行偏移量调整后(说的简单点就是对左上右下的x、y坐标进行上下左右调整),再次重复Pnet所述的IOU NMS干掉大部分的候选。最终Pnet输出的也是(num_left_after_Rnet, 16),根据bbox的坐标再去原图截出图片输入到Onet,同样也是根据最大边长的正方形截取方法,避免形变和保留更多细节。
O-NET
经过Rnet干掉很多候选后的图片输入到Onet,输出准确的bbox坐标和landmark坐标。大体可以重复Pnet的过程,不过有区别的是这个时候我们除了关注bbox的坐标外,也要输出landmark的坐标。(有小伙伴会问,前面不关注landmark的输出吗?嗯,作者认为关注的很有限,前面之所以也有landmark坐标的输出,主要是希望能够联合landmark坐标使得bbox更精确,换言之,推理阶段的Pnet、Rnet完全可以不用输出landmark,Onet输出即可。当然,训练阶段Pnet、Rnet还是要关注landmark的)经过分类筛选、框调整后的NMS筛选,好的,至此我们就得到准确的人脸bbox坐标和landmark点了,任务完满结束。
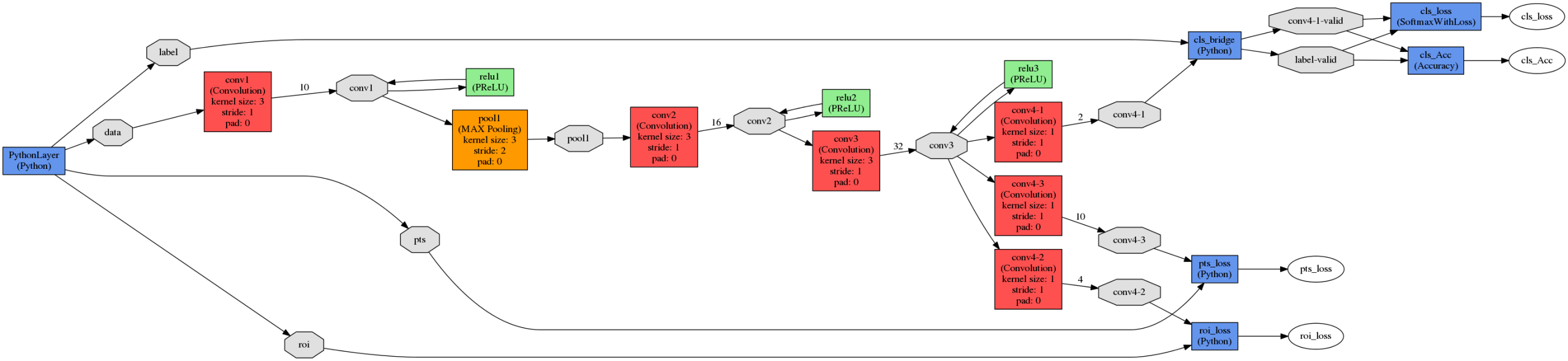
网络的整体结构
训练
我们利用三个任务来训练我们的CNN检测器:人脸/非人脸分类、边界框回归和人脸地标定位。
1)人脸分类:将学习目标表述为一个两类分类问题。对于每个样本,我们使用交叉熵损失:
2)边框回归:对于每一个候选窗口,我们预测它与最近的ground truth(即距离)之间的偏移量。,即边框的左上角、高度和宽度)。学习目标被表述为一个回归问题,我们对每个样本使用欧几里得损失:
3)人脸关键点定位:
最小化欧式距离损失函数
常见问题
Q1:您使用什么数据库?
A1:类似于官方文件,Wider Face用于检测,而CelebA用于对齐。
Q2:“ 12(24/48)net-only-cls.caffemodel”文件的作用是什么?
A2:提供初始重量进行训练。 由于caffe的初始权重是随机的,因此糟糕的初始权重可能需要很长时间才能收敛,甚至在此之前可能过度拟合。