模块一:基础
1,数据库三大范式
第一范式:属性的原子性
第二范式:在第一范式的基础上,非主键列完全依赖于主键,而不能是依赖于主键的一部分。消除主键和其他键的部分依赖。
第三范式:在第二范式的基础上,非主键只依赖主键,不依赖其他的。消除传递函数依赖。
还有一个最牛范式:BC范式
2,mysql有关权限的表有哪些?
- user权限表:记录允许连接到服务器的用户帐号信息,里面的权限是全局级的。
- db权限表:记录各个帐号在各个数据库上的操作权限。
- table_priv权限表:记录数据表级的操作权限。
- columns_priv权限表:记录数据列级的操作权限。
- host权限表:配合db权限表对给定主机上数据库级操作权限作更细致的控制。这个权限表不受GRANT和REVOKE语句的影响。
3,Mysql的数据类型
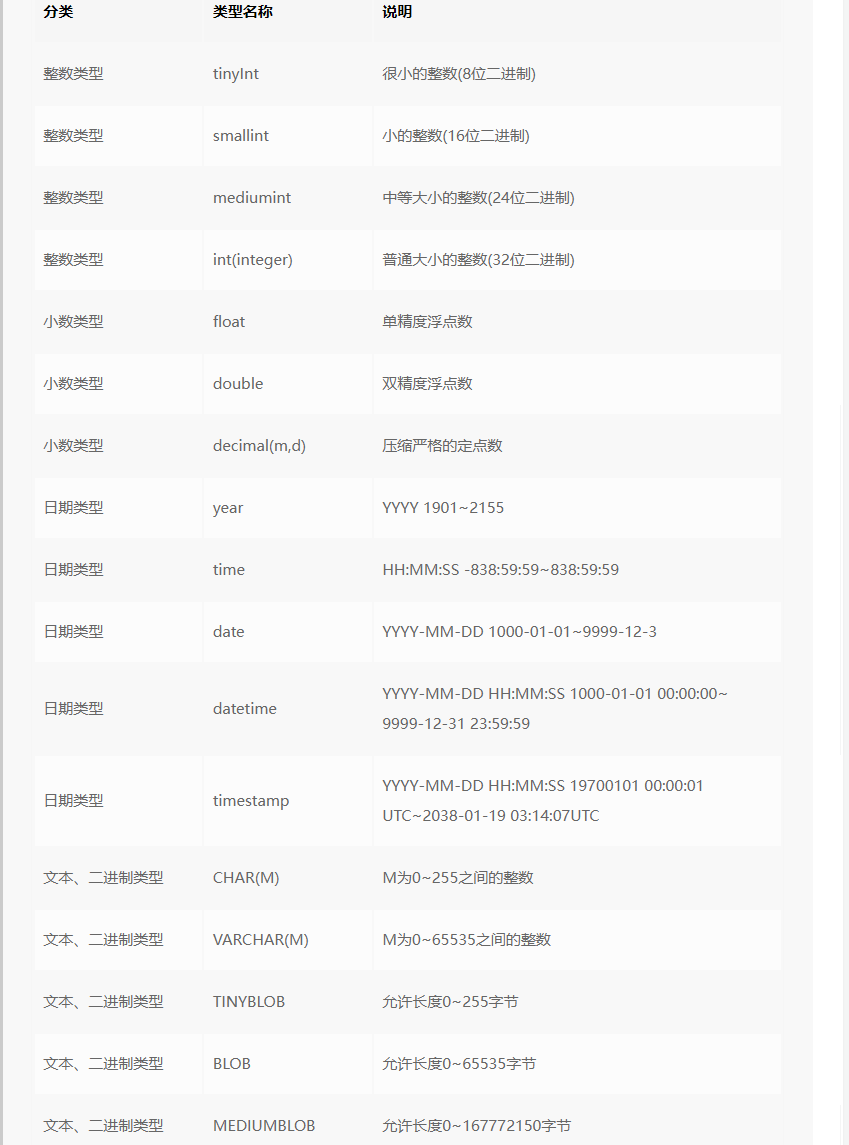
还有很多。
模块二:引擎
常用的就是InnoDB和MyIsam。
InnoDB是mysql的默认引擎。
- InnoDB和MyIsam有什么区别?
InnoDB:支持事务,支持外键,自动热备份,支持行级锁,支持哈西索引。
MyIsam:支持表级锁,支持全文搜索。
- InnoDB和MyIsam索引的区别
InnoDB是聚簇索引,MyIsam是非聚簇索引。
(简要说说两种索引区别,聚簇索引存储索引和数据,非聚簇的叶子节点不是数据是指向数据的地址,然后数据还在磁盘里,所以速度慢)
InnoDB的主键索引的叶子节点存储着行数据,因此主键索引非常高效。MyISAM索引的叶子节点存储的是行数据地址,需要再寻址一次才能得到数据。(其实就是索引)
- InnoDB引擎的四大特性
插入缓冲(insert buffer)
二次写(double write)
自适应哈希索引(ahi)
预读(read ahead)
模块三:索引
索引是一种数据结构,通常使用B树和B+树。
用于快速遍历查找数据。
- 索引分类
1,主键索引:为了保持数据库表与表之间的关系,不允许空
2,唯一索引:每个值不同,允许有一个空
3,联合索引:多个键一起索引,要符合最左前缀原则。
4,聚集索引
5,非聚集索引
6,全文索引
InnoDB索引
重点看这个。
- 聚簇索引/主键索引/聚集索引
InnoDB每张表都有一个聚簇索引,用B+树实现。叶子节点存储整行数据。
- 辅助索引
辅助索引的叶子节点存储主键值,再通过这个主键值查询聚簇索引里的数据。
- 联合索引
有最左前缀匹配原则,遇到范围查找,后面的条件就不过去了。
- 回表
我们通过辅助索引查到主键,再通过聚簇索引查值,就很浪费性能。
- 如何优化回表呢?
使用覆盖索引,通过查找非主键索引获取的数据已经满足,不需要回表去主键查找。
实现的话,就是非主键列的数据联合索引,就可以了。
- B树,B+树,红黑树
B树和B+树是多路搜索树,B树节点里有存数据,B+树只在叶子节点存数据。
红黑树是二叉搜索树,不合理。
- 哈希索引
蛮不错的,但是不支持范围查找。
模块四:事务
- 什么是事务
不可分割的数据库操作序列,要么都执行,要么都不执行。
- 事务的四大特性:
原子性:事务是最小的执行单元,不可以分割,要么全部执行,要么不执行。
一致性:执行前后,数据保持一致。如你转我200,你少200的同时,我必须多200。
隔离性:并发访问数据库的时候,一个事务不能被其他事务干扰。
持久性:事务提交之后,对数据库的改变是持久的。
- InnoDB通过什么来保证四个特性?
原子性和持久性通过redo log(重做日志)日志和undo log(回滚日志)来保证。
隔离性通过MVCC和锁机制来保证。
一致性通过三个性质来保证。
- 事务并发会出现什么问题
脏读:一个事务读取到了另外一个事务未提交的数据。
不可重复读:在一个事务内,重复读取某个数据的值,得到结果不一样。
幻读:一个事务内,重复查询某符合条件的记录数量,数量不同。
- 事务的隔离级别
读未提交:不管有没有事务提交,修改就能别其他事务看见。
读已提交:事务提交后,其他事务才能看到新的数据。
重复读:一个事务重复读取,结果不变。
串行化:给记录加上了读写锁,如果出现读写冲突,会等到当前事务结束后,才继续流程。
- 隔离级别出现的问题
读未提交:脏读,幻读,不可重复读
- 如何实现隔离级别
读未提交:啥也别加就是。
读已提交:使用快照
模块五:日志
InnoDB的事务日志undo log和redo log,自带的开发日志bin log。