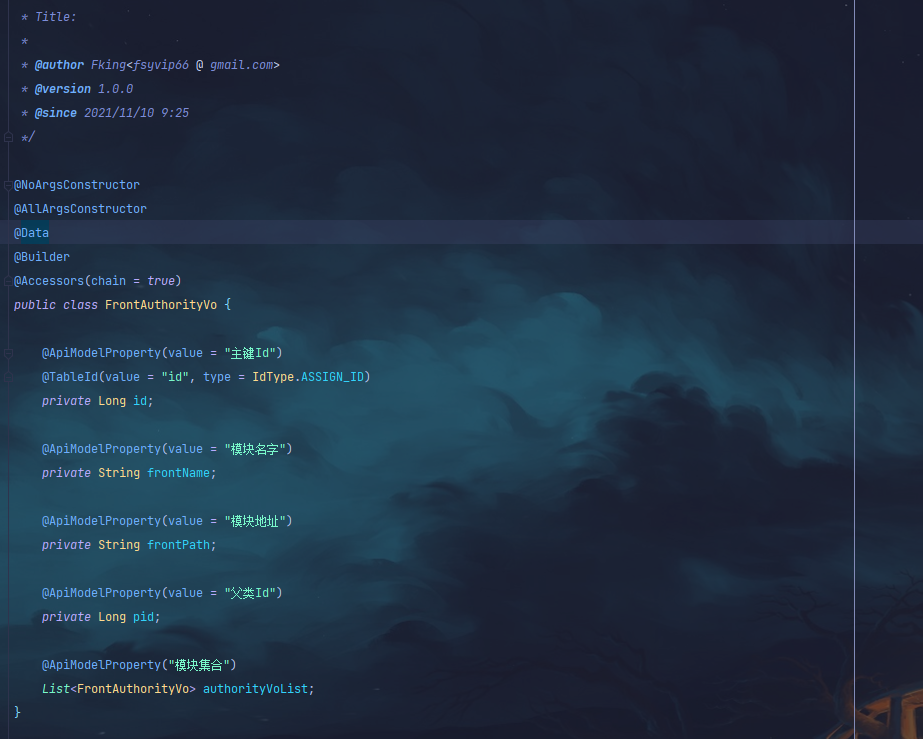
1:首先编写需要实体类
具备参数:
主键ID
父类ID:这里我使用PID
本类集合
其余参数根据需求指定
2:思路整理
首先根据需求查询数据库中对应的数据子类父级ID对应父类ID全部查出来。
frontAuthorityMapper.selectList(new QueryWrapper<>()).stream().parallel().map(frontAuthority ->
FrontAuthorityVo.builder().frontName(frontAuthority.getFrontName()).pid(frontAuthority.getPid()).id(frontAuthority.getId()).frontPath(frontAuthority.getFrontPath()).build()).collect(Collectors.toList())我这里使用了MP无条件查出来数据库中所有数据
然后用Vo序列化数据
stream() :Java 8 API添加了一个新的抽象称为流Stream,可以让你以一种声明的方式处理数据。
Stream 使用一种类似用 SQL 语句从数据库查询数据的直观方式来提供一种对 Java 集合运算和表达的高阶抽象。
Stream API可以极大提高Java程序员的生产力,让程序员写出高效率、干净、简洁的代码。
这种风格将要处理的元素集合看作一种流, 流在管道中传输, 并且可以在管道的节点上进行处理, 比如筛选, 排序,聚合等。
元素流在管道中经过中间操作(intermediate operation)的处理,最后由最终操作(terminal operation)得到前面处理的结果。
parallel():并行流这里我的数据量不大,所以效果并不明显 如果数据量打的话 在保证线程安全的同时 使用并行流效果会快一倍。
当然也可以使用:parallerlStream() 当然新特性还有很多这里就不过多介绍了
Collectors.toList():Collectors 类实现了很多归约操作,例如将流转换成集合和聚合元素Collectors 可用于返回列表或字符串
如果想看实现流程可以去看下一stream的源码
mapInfo.stream().filter(daddyInfo -> (daddyInfo.getPid() == 0)).collect(Collectors.toList());
fatherInfo.forEach(info -> buildSubs(info, mapInfo.stream().filter(sonInfo -> (sonInfo.getPid() != 0)).collect(Collectors.toList())))然后使用filter():过滤掉PID不等于0的 ==等于父类 过滤掉PID等于0的 ==等于子类
3:效果图
正文完