架构
前后端分离:
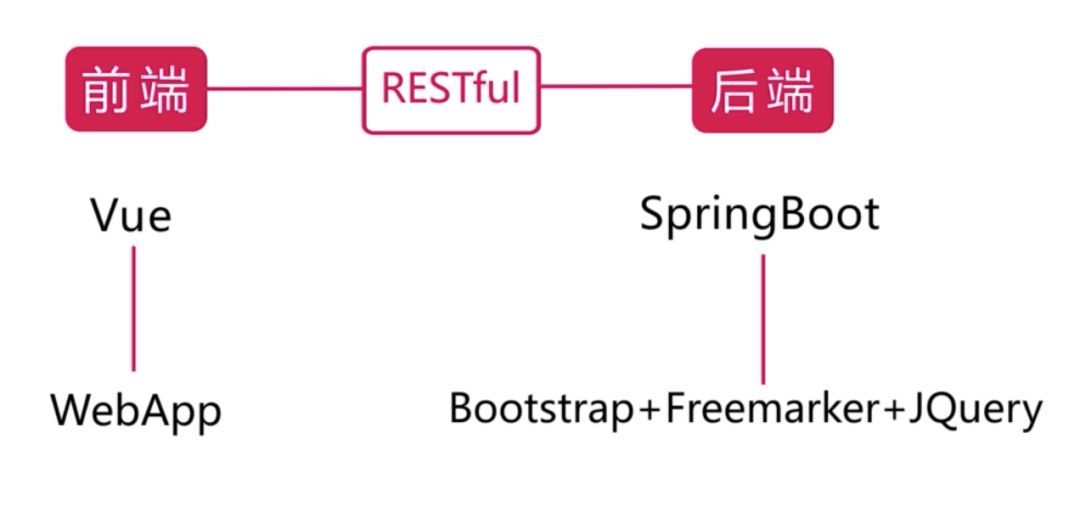
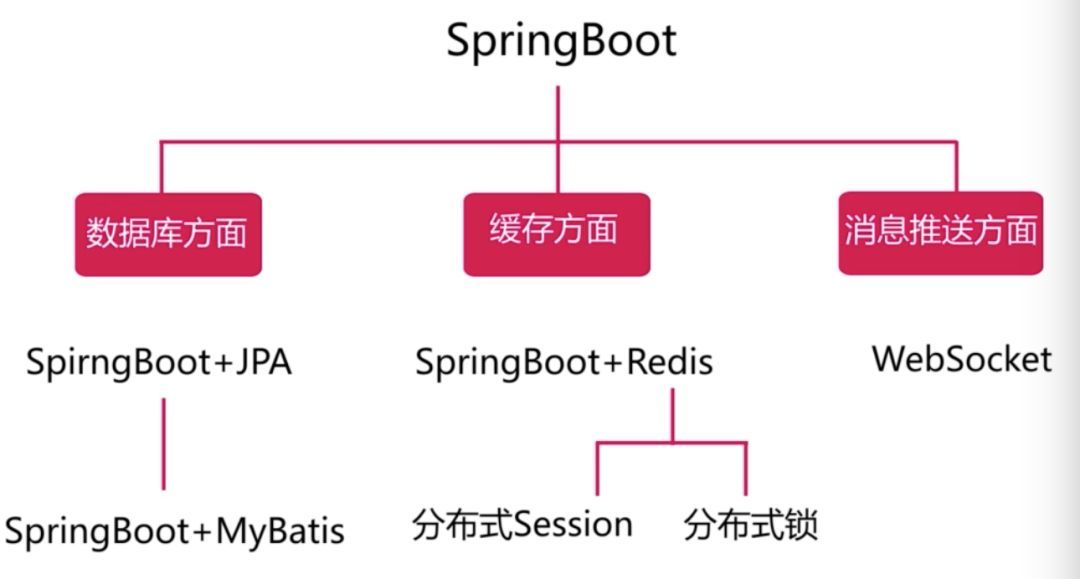
部署架构:
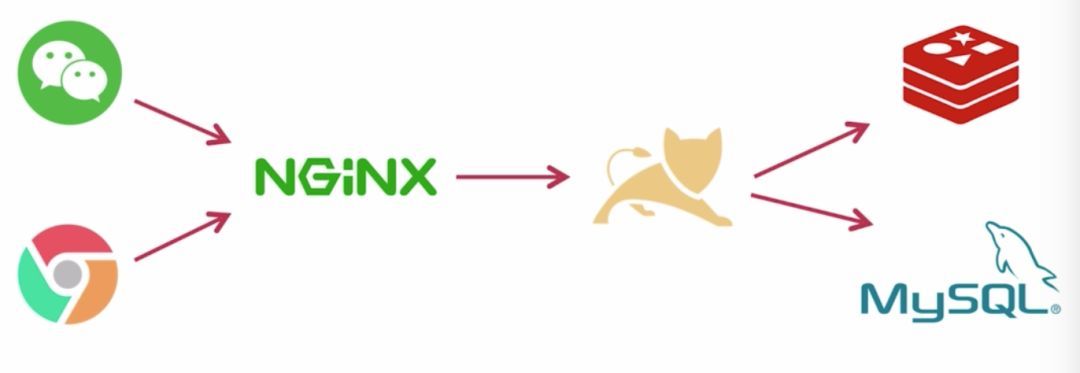
补充:
- setting.xml 文件的作用:settings.xml是maven的全局配置文件。而pom.xml文件是所在项目的局部配置。Settings.xml中包含类似本地仓储位置、修改远程仓储服务器、认证信息等配置。
- maven的作用:借助Maven,可将jar包仅仅保存在“仓库”中,有需要该文件时,就引用该文件接口,不需要复制文件过来占用空间。
注:这个“仓库”应该就是本地安装maven的目录下的Repository的文件夹
分布式锁
线程锁:当某个方法或代码使用锁,在同一时刻仅有一个线程执行该方法或该代码段。线程锁只在同一JVM中有效,因为线程锁的实现在根本上是依靠线程之间共享内存实现的。如synchronized
进程锁:为了控制同一操作系统中多个进程访问某个共享资源。
分布式锁:当多个进程不在同一个系统中,用分布式锁控制多个进程对资源的访问。
分布式锁一般有三种实现方式:
- 数据库乐观锁;
- 基于Redis的分布式锁;
- 基于ZooKeeper的分布式锁。
乐观锁的实现:使用版本标识来确定读到的数据与提交时的数据是否一致。提交后修改版本标识,不一致时可以采取丢弃和再次尝试的策略。
分布式锁基于Redis的实现:(本系统锁才用的)
基本命令:
- SETNX(SET if Not exist):当且仅当 key 不存在,将 key 的值设为 value ,并返回1;若给定的 key 已经存在,则 SETNX 不做任何动作,并返回0。
- GETSET:将给定 key 的值设为 value ,并返回 key 的旧值。先根据key获取到旧的value,再set新的value。
- EXPIRE 为给定 key 设置生存时间,当 key 过期时,它会被自动删除。
加锁方式:
这里的jedis是Java对Redis的集成
jedis.set(String key, String value, String nxxx, String expx, int time)错误的加锁方式1:
如果程序在执行完setnx()之后突然崩溃,导致锁没有设置过期时间。那么将会发生死锁。
Long result = jedis.setnx(Key, value);
if (result == 1) {
// 若在这里程序突然崩溃,则无法设置过期时间,将发生死锁
jedis.expire(Key, expireTime);
}错误的加锁方式2:
分布式锁才用(Key,过期时间)的方式,如果锁存在,那么获取它的过期时间,如果锁的确已经过期了,那么获得锁,并且设置新的过期时间
错误分析:不同的客户端之间需要同步好时间。
long expires = System.currentTimeMillis() + expireTime;
String expiresStr = String.valueOf(expires);
// 如果当前锁不存在,返回加锁成功
if (jedis.setnx(lockKey, expiresStr) == 1) {
return true;
}
// 如果锁存在,获取锁的过期时间
String currentValueStr = jedis.get(lockKey);
if (currentValueStr != null && Long.parseLong(currentValueStr) < System.currentTimeMillis()) {
// 锁已过期,获取上一个锁的过期时间,并设置现在锁的过期时间
String oldValueStr = jedis.getSet(lockKey, expiresStr);
if (oldValueStr != null && oldValueStr.equals(currentValueStr)) {
// 考虑多线程并发的情况,只有一个线程的设置值和当前值相同,它才有权利加锁
return true;
}
}
// 其他情况,一律返回加锁失败
return false;解锁:判断锁的拥有者后可以使用 jedis.del(lockKey) 来释放锁。
分布式锁基于Zookeeper的实现
Zookeeper简介:Zookeeper提供一个多层级的节点命名空间(节点称为znode),每个节点都用一个以斜杠(/)分隔的路径表示,而且每个节点都有父节点(根节点除外)。
例如,/foo/doo这个表示一个znode,它的父节点为/foo,父父节点为/,而/为根节点没有父节点。
client不论连接到哪个Server,展示给它都是同一个视图,这是zookeeper最重要的性能。
Zookeeper 的核心是原子广播,这个机制保证了各个Server之间的同步。实现这个机制的协议叫做Zab协议。Zab协议有两种模式,它们分别是恢复模式(选主)和广播模式(同步)。当服务启动或者在领导者崩溃后,Zab就进入了恢复模式,当领导者被选举出来,且大多数Server完成了和 leader的状态同步以后,恢复模式就结束了。状态同步保证了leader和Server具有相同的系统状态。
为了保证事务的顺序一致性,zookeeper采用了递增的事务id号(zxid)来标识事务,实现中zxid是一个64位的数字。
Zookeeper的分布式锁原理
获取分布式锁的流程:
- 在获取分布式锁的时候在locker节点(locker节点是Zookeeper的指定节点)下创建临时顺序节点,释放锁的时候删除该临时节点。
- 客户端调用createNode方法在locker下创建临时顺序节点,然后调用getChildren(“locker”)来获取locker下面的所有子节点,注意此时不用设置任何Watcher。
- 客户端获取到所有的子节点path之后,如果发现自己创建的子节点序号最小,那么就认为该客户端获取到了锁。
- 如果发现自己创建的节点并非locker所有子节点中最小的,说明自己还没有获取到锁,此时客户端需要找到比自己小的那个节点,然后对其调用exist()方法,同时对其注册事件监听器。
- 之后,让这个被关注的节点删除,则客户端的Watcher会收到相应通知,此时再次判断自己创建的节点是否是locker子节点中序号最小的,如果是则获取到了锁,如果不是则重复以上步骤继续获取到比自己小的一个节点并注册监听。
我的解释:
A在Locker下创建了Node_n —>循环 ( 每次获取Locker下的所有子节点 —> 对这些节点按节点自增号排序顺序 —> 判断自己创建的Node_n是否是第一个节点 —> 如果是则获得了分布式锁 —> 如果不是监听上一个节点Node_n-1 等它释放掉分布式锁。)
@ControllerAdvice处理全局异常
Mybatis注解方式的使用:
@insert 用注解方式写SQL语句
分布式系统的下的Session
1、分布式系统:多节点,节点发送数据交互,不共享主内存,但通过网络发送消息合作。
分布式:不同功能模块的节点
集群:相同功能的节点
2、Session 与token
服务端在HTTP头里设置SessionID而客户端将其保存在cookie
而使用Token时需要手动在HTTP头里设置,服务器收到请求后取出cookie进行验证。
都是一个用户一个标志
3、分布式系统中的Session问题:
高并发:通过设计保证系统能够同时并行处理很多请求。
当高并发量的请求到达服务端的时候通过负载均衡的方式分发到集群中的某个服务器,这样就有可能导致同一个用户的多次请求被分发到集群的不同服务器上,就会出现取不到session数据的情况。
根据访问不同的URL,负载到不同的服务器上去
三台机器,A1部署类目,A2部署商品,A3部署单服务
通用方案:用Redis保存Session信息,服务器需要时都去找Redis要。登录时保存好key-value,登出时让他失效
垂直扩展:IP哈希 IP的哈希值相同的访问同一台服务器
session的一致性:只要用户不重启浏览器,每次http短连接请求,理论上服务端都能定位到session,保持会话。
Redis作为分布式锁
高并发:通过设计保证系统能够同时并行处理很多请求。
同步:Java中的同步指的是通过人为的控制和调度,保证共享资源的多线程访问成为线程安全。
线程的Block状态:
a.调用join()和sleep()方法,sleep()时间结束或被打断
b.wait(),使该线程处于等待池,直到notify()/notifyAll():不释放资源
此外,在runnable状态的线程是处于被调度的线程,Thread类中的yield方法可以让一个running状态的线程转入runnable。
Q:为什么wait,notify和notifyAll必须与synchronized一起使用?Obj.wait()、Obj.notify必须在synchronized(Obj){…}语句块内。
A:wait就是说线程在获取对象锁后,主动释放对象锁,同时本线程休眠。
Q:Synchronized:
A:Synchronized就是非公平锁,它无法保证等待的线程获取锁的顺序。
公平和非公平锁的队列都基于锁内部维护的一个双向链表,表结点Node的值就是每一个请求当前锁的线程。公平锁则在于每次都是依次从队首取值。
ReentrantLock重入性:
Spring + Redis缓存的两个重要注解:
- @cacheable 只会执行一次,当标记在一个方法上时表示该方法是支持缓存的,Spring会在其被调用后将其返回值缓存起来,以保证下次利用同样的参数来执行该方法时可以直接从缓存中获取结果。
- @cacheput:与@Cacheable不同的是使用@CachePut标注的方法在执行前不会去检查缓存中是否存在之前执行过的结果,而是每次都会执行该方法,并将执行结果以键值对的形式存入指定的缓存中。
对数据库加锁(乐观锁 与 悲观锁)
悲观锁依赖数据库实现:
select * from account where name=”Erica” for update这条sql 语句锁定了account 表中所有符合检索条件(name=”Erica”)的记录,使该记录在修改期间其它线程不得占有。
代码层加锁:
String hql ="from TUser as user where user.name='Erica'";
Query query = session.createQuery(hql);
query.setLockMode("user",LockMode.UPGRADE); //加锁
List userList = query.list();//执行查询,获取数据其它
@Data 类似于自动生成了Getter()、Setter()、ToString()等方法。
JAVA1.8的新特性StreamAPI:Collectors中提供了将流中的元素累积到汇聚结果的各种方式
List<Menu> menus=Menu.getMenus.stream().collect(Collectors.toList())For – each 写法:
for each语句是java5新增,在遍历数组、集合的时候,for each拥有不错的性能。
public static void main(String[] args) {
String[] names = {"beibei", "jingjing"};
for (String name : names) {
System.out.println(name);
}
}for each虽然能遍历数组或者集合,但是只能用来遍历,无法在遍历的过程中对数组或者集合进行修改。
BindingResult:一个@Valid的参数后必须紧挨着一个BindingResult 参数,否则spring会在校验不通过时直接抛出异常。
@Data
public class OrderForm {
@NotEmpty(message = "姓名必填")
private String name;
}后台:
@RequestMapping("save")
public String save( @Valid OrderForm order,BindingResult result) {
//
if(result.hasErrors()){
List<ObjectError> ls=result.getAllErrors();
for (int i = 0; i < ls.size(); i++) {
log.error("参数不正确,OrderForm={}", order);
throw new SellException(
………… ,
result.getFeildError.getDefaultMessage()
)
System.out.println("error:"+ls.get(i));
}
}
return "adduser";
}result.getFeildError.getDefaultMessage()可抛出“姓名必填” 的异常。
4、List转为Map
public class Apple {
private Integer id;
private String name;
private BigDecimal money;
private Integer num;
/*构造函数*/
}List<Apple> appleList = new ArrayList<>();//存放apple对象集合
Apple apple1 = new Apple(1,"苹果1",new BigDecimal("3.25"),10);
Apple apple12 = new Apple(1,"苹果2",new BigDecimal("1.35"),20);
Apple apple2 = new Apple(2,"香蕉",new BigDecimal("2.89"),30);
Apple apple3 = new Apple(3,"荔枝",new BigDecimal("9.99"),40);
appleList.add(apple1);
appleList.add(apple12);
appleList.add(apple2);
appleList.add(apple3);Map<Integer, Apple> appleMap =
appleList.stream().collect(Collectors.toMap(Apple::getId, a -> a,(k1,k2)->k1));5、Collection的子类:List、Set
List:ArrayList、LinkedList 、Vector
List:有序容器,允许null元素,允许重复元素
Set:元素是无序的,不允许元素
最流行的是基于 HashMap 实现的 HashSet,由hashCode()和equals()保证元素的唯一性。
可以用set帮助去掉List中的重复元素,set的构造方法的参数可以是List,构造后是一个去重的set。
HashMap的补充:它不是Collection下的
Map可以使用containsKey()/containsValue()来检查其中是否含有某个key/value。
HashMap会利用对象的hashCode来快速找到key。
插入过程:通过一个hash函数确定Entry的插入位置index=hash(key),但是数组的长度有限,可能会发生index冲突,当发生了冲突时,会使用头插法,即为新来的Entry指向旧的Entry,成为一个链表。
每次插入时依次遍历它的index下的单链表,如果存在Key一致的节点,那么直接替换,并且返回新的值。
但是单链表不会一直增加元素,当元素个数超过8个时,会尝试将单链表转化为红黑树存储。
源码地址:https://github.com/923310233/wxOrder