浏览器原理学习笔记03—V8工作原理
Write By CS逍遥剑仙
我的主页: www.csxiaoyao.com
GitHub: github.com/csxiaoyaojianxian
Email: [email protected]
1. JavaScript 的数据类型
JavaScript 是弱类型(支持隐式类型转换),动态(运行时类型推断)语言。
JavaScript 的数据类型有 8 种:7 种 原始类型 和 引用类型 (对象)

2. JavaScript 内存空间
2.1 内存模型
function foo(){
var a = "1"
var b = a
var c = {name:"1"}
var d = c
}
foo()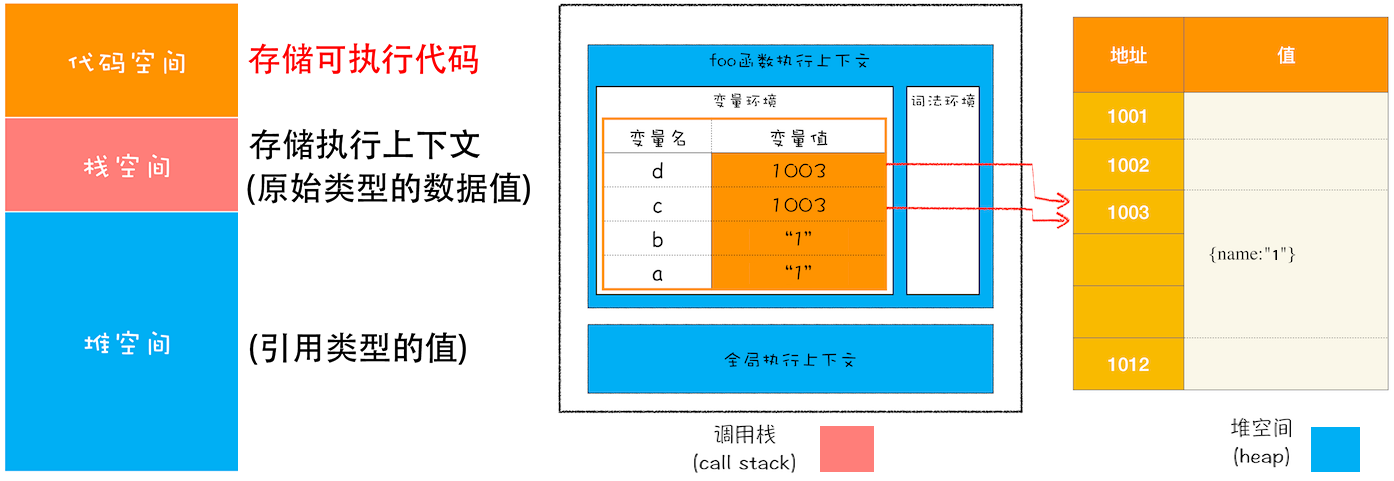
栈空间通常不会设置太大,存放原始类型的小数据;堆空间很大,存放引用类型的数据,分配和回收内存会占用一定时间。
2.2 闭包对象产生过程
function foo() {
var myName = "1"
let test1 = 1
const test2 = 2
var innerBar = {
setName:function(newName){
myName = newName
},
getName:function(){
console.log(test1)
return myName
}
}
return innerBar
}
var bar = foo()
bar.setName("test")
bar.getName()- foo 函数执行并创建执行上下文;
- 预扫描 内部函数,编译过程中遇到内部函数如
setName、getName则对内部函数进行 快速词法扫描,发现引用了外部函数变量如myName、test1则判断为闭包,在堆空间创建closure(foo)对象(内部对象 JavaScript 无法访问)来存储闭包变量如myName、test1; - 未被内部函数引用的变量如
test2仍旧保存在调用栈中; - 当 foo 函数退出,
clourse(foo)依然被其内部的getName和setName方法引用。所以在下次调用bar.setName或bar.getName时,创建的执行上下文中就包含了clourse(foo)。
3. 自动垃圾回收
3.1 调用栈中的数据回收
JavaScript 引擎通过向下移动 ESP (记录当前执行状态的指针) 来销毁函数保存在栈中的执行上下文,效率很高。
function foo(){
var a = 1
var b = {name:"test1"}
function showName(){
var c = "1"
var d = {name:"test2"}
}
showName()
}
foo()3.2 堆中的数据回收
3.2.1 代际假说和分代收集
代际假说:
大部分对象在内存中存在的时间很短
短期不死的对象,会活得更久
堆中的垃圾数据使用 JavaScript 中的垃圾回收器进行回收。V8 把堆分为 新生代 和 老生代 两个区域,新生代中存放生存时间短的对象,老生代中存放生存时间久的对象。新生区通常只支持 1~8M 的容量,使用 副垃圾回收器 进行回收。老生区支持的容量较大,使用 主垃圾回收器 进行回收。
3.2.2 副垃圾回收器
新生代中用 Scavenge 算法 (空间对半划分为对象区域和空闲区域) 来处理。
新对象存放到对象区域,当对象区域快满时执行一次垃圾清理,先对对象区域中的垃圾做标记,再将存活的对象有序复制到空闲区域中,相当于完成了内存整理操作。完成复制后两个角色翻转,完成了垃圾清理。
因为复制时间不宜过长,一般新生区空间会设置得比较小,也因此很容易填满,JavaScript 引擎采用了 对象晋升策略 来解决,即经过两次垃圾回收依然存活的对象会被移动到老生区中。
3.2.3 主垃圾回收器
老生区中的对象占用空间大、存活时间长,一部分来自新生区中晋升的对象,一部分来自直接分配的大对象。
老生代采用 标记 – 清除 (Mark-Sweep) 算法进行垃圾回收。标记阶段从调用栈根元素开始递归遍历,根据能否到达区分 活动对象 和 垃圾数据。
垃圾清除阶段清除垃圾数据并产生大量不连续的内存碎片。再使用 标记 – 整理 (Mark-Compact) 算法在标记后将所有存活的对象移向一端,再直接清理边界以外的内存空间。
3.2.4 全停顿
由于 JavaScript 运行在渲染进程主线程上,执行垃圾回收将导致暂停执行 JavaScript 脚本,即 全停顿 (Stop-The-World)。为减少全停顿,V8 将标记过程分为多个的子标记过程,与 JavaScript 应用逻辑交替进行,直到标记阶段完成,称作 增量标记 (Incremental Marking) 算法。
4. 编译器和解释器
4.1 V8 执行 JavaScript 代码总览
编译器和解释器的区别。
JavaScript 是解释型语言,V8 执行 JavaScript 代码的流程总览。
4.2 生成抽象语法树(AST)和执行上下文
4.2.1 AST 的应用
var myName = "sunshine"
function foo(){
return 18;
}
myName = "csxiaoyao"
foo()经过 javascript-ast 处理后生成的 AST 结构如下:
AST 是非常重要的一种数据结构,编译器或解释器依赖于 AST,而非源代码。AST 在很多项目中有着广泛的应用,如:
- Babel 的工作原理是先将 ES6 源码转换为 AST,再将 ES6 语法的 AST 转换为 ES5 语法的 AST,最后利用 ES5 的 AST 生成 JavaScript 源代码
- ESLint 将源码转换为 AST,再利用 AST 来检查代码规范化的问题
4.2.2 AST 的生成
生成 AST 需要经历分词和解析两个阶段。
1. 分词 / 词法分析 (tokenize)
将源码拆解成一个个语法上不可再分、最小的单个字符或字符串 token
2. 解析 / 语法分析 (parse)
将 token 根据语法规则转为 AST
4.3 生成字节码
生成 AST 和执行上下文后,解释器 Ignition 会根据 AST 生成字节码,并解释执行字节码。
引入字节码是为了解决起初 V8 直接将 AST 转换为机器码而导致移动设备内存占用高的问题,字节码就是介于 AST 和机器码之间的一种代码,与特定类型的机器码无关,字节码需要通过解释器将其转换为机器码后才能执行。
4.4 执行代码 & JIT
第一次执行的字节码,解释器 Ignition 会逐条解释执行。在执行字节码的过程中,如果发现有热点代码(HotSpot),即一段代码被重复执行多次,后台编译器 TurboFan 会把该段热点字节码编译为高效的机器码,提高后续执行效率。字节码配合解释器和编译器的技术称为 即时编译 (JIT)。
4.5 JavaScript 性能优化策略
- 提升单次脚本的执行速度,避免 JavaScript 的长任务霸占主线程,使得页面快速响应交互;
- 避免大的内联脚本,因为在解析 HTML 的过程中,解析和编译也会占用主线程;
- 减少 JavaScript 文件的容量,提升下载速度,并且占用更低的内存。