水晶帘动微风起,满架蔷薇一院香。
本系列文章的前几篇讲解了几种算法,.冒泡排序,插入排序,选择排序,但是,也许你会感觉到,这几个算法除了偶尔面试中会和面试官聊上几句,实际的编程时间,几乎没有再使用过这几个排序算法,即使真的有必要去排序一个数组,编程语言中也已经为我们内置好了排序算法,大部分编程语言中内置的是快速排序,那么这个与递归有什么关系呢?
快速排序
快速排序效率快,依赖于它的算法巧妙,首先,这里面就有一个分区的概念,分区也就是从数组中选取一个值,把它当作一个分界点,我们为了好讲解,与读者约定一下,这个分界点的值就叫它二狗子吧,开个玩笑,我们把它称之为轴好了,然后比较这个数组中的其它的值,如果这个值比轴小,就放在轴的左边,如果这个值比轴大,那么就把它放到轴的右边.听起来很简单,就好像一个分类的游戏.
看如下一个数组
0 5 2 1 6 3 如果我们把1当做轴的话,分一下类
比1小的数字只有0,
比1大的数字就有2 3 5 6
然后将1放在这2者之间
但是在计算机中我们需要用计算机的方法来解决问题,并且还要解决的很巧妙.
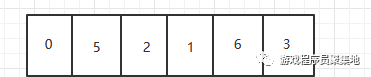
在这里为了好演示,我把最后一个数字3当做轴 ,所以要把3单独提出来
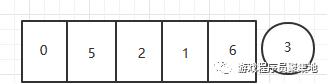
第一步,
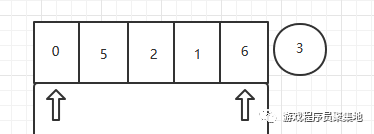
左指针的值与轴比较,发现0<3,这表示起码到目前为止,0的位置是对的,然后左指针右移
发现5>3,这个5不是放在了正确的位置,但是它要和谁来交换呢?因为之前学过的算法,里面的思想就是一旦发现了大小不同,就要和某个中间值或者比较值交换,而这里不是这么做的,假如现在5的这里不是放5,而是1,那么1<3,这个左指针还是要继续向右移动,也就是说,当左指针看到某个数字没有放在正确的位置的时候,这个时候指针就停在这里了.那么这个时候停在这里干什么呢?不要忘了我们还有一个右指针.我们读取右指针的值.
读取到了6的值,发现它比3也大,那怎么办呢?左指针指向比3大的值,右指针指向的也比3大,难道也要停在这里吗?实际上并不是,左指针找比3大的值,右指针找比3小的值,所以右指针的值并不满足,所以右指针要向左移.
这时,右指针指向的值为1,这时候1<3 条件满足了,左指针要找的比3大的值找到了,停在了那里,右指针找比3小的值现在也找到了,也停在了那里,按道理程序应该做点什么.接下来就要交换它们的值,它们一交换之后,左指针可以继续向右移来寻找下一个比3大的值了,等到左指针找到后右指针同样也可以继续找比3小的值了.
那么左指针继续向右寻找比3大的值,发现是2 ,条件不满足
还要继续向右移动,但是这个时候左指针和右指针已经重合了,
虽然是重合了,但是第一步还是要判断左指针是不是找到了正确的值了,发现5>3,按照道理应该是移动右指针,但是这里指针指向已经重合了,那怎么办呢?其实这就到了分区的最后一步了,将轴与满足条件的指针指向的值调换.
虽然这一趟走过来没有排好序,但是3已经在正确的位置上了.
那么我们来总结一下,首先是一个数组,找到这个数组最后的一个值(其实可以是随机的)然后用左右指针比较的方法来确定这个轴应该放在哪个位置的.你应该发现了,3的左边是完全可以当成一个数组来快速排序的,同样的,3的右边也是可以当成一个数组来排序的,你应该想到了吧,这完全就是递归算法的完美实现啊.
using System.Collections;
using System.Collections.Generic;
using UnityEngine;
public class quick : MonoBehaviour {
int[] number = new int[] { , , , , , , , , , };
// Use this for initialization
void Start () {
Sort(number, , number.Length - );
}
//每一次快排
int quickSort(int[] array, int begin, int end)
{
int temp = array[begin];//比较的值,可以是随机的值
//后面的值大于中间值
while (array[end] >= temp && end > begin)
end--;
array[begin] = array[end];
//前面的值小于中间值
while (array[begin] <= temp && end > begin)
begin++;
array[end] = array[begin];
array[begin] = temp;
foreach (var item in array)
{
Debug.Log("\t" + item);
}
return end;
}
void Sort(int[] array, int begin, int end)
{
if (begin >= end)
return;
int index = quickSort(array, begin, end);
//左边的单元
Sort(array, begin, index -1);
//右边的单元
Sort(array, index + , end);
}
}
效率问题
我们发现快速排序其实和其它的排序算法一样,包含2个步骤
- 比较 每个值都要与轴比较 那么就是N-1
- 交换 满足条件的时候交换3个指针的值,这里最少需要交换一次那么分析到最坏的情况,交换得次数就是N/2.注意,这里并不是N-1,因为指针交换之后就下次就不用再读了直接移到下一个上面了.
所以这里就相当于格子中得7与1交换,6与2交换,5与3交换.那么这是最坏得情况下,对于随机排列得数组,粗略得算来大概也就是N/4,于是N次的比较加上N/4次的交换,换算下来就是1.25N,由于大O记法有忽略常数,所以分区操作的步骤步数是O(N).是不是看到了久违的大O记法了.注意,这里只是说了分区.没有说快速排序.
快速排序最坏的情况就是每次分区都使轴落在数组的开头或结尾。导致这种情况的原因有好几种,包括数组已升序排列,或已降序排列。
虽然在此情况下长度为8的数组每次分区都只有一次交换,但比较的次数却变得很多。在轴总落在中央的例子里,每次分区都能划分出比原数组小得多的子数组(过程中产生的最大的子数组长度为4),使各部分都能很快地到达基准情形。然而如果轴落在其中一端,前5次分区就需要处理长度大于4的数组。而且这s次分区里,每次所需的比较次数还是和子数组的元素量一样多。
所以到最后大O记法为O(N^2).
总结
由于运用了递归,快速排序和快速选择可以将棘手的问题解决得既巧妙又高效。这也提醒了我们,有些看上去很普通的算法,可能是经过反复推敲的高性能解法。
其实能递归的不只有算法,还有数据结构。后面将要接触的链表、二叉树以及图,就利用了自身递归的特性,给我们提供了迅速的数据操作方式。
…END…