记得之前面试官谈谈啥是眺表,应用场景有些什么?
跳表全称叫做跳跃表,简称跳表。跳表是一个随机化的数据结构,实质是一种可以进行二分查找的有序链表。跳表在原有的有序链表上增加了多级索引,通过索引来实现快速查询。跳表不仅能提高搜索性能,同时也可以提高插入和删除操作的性能。
单纯的看定义还是有些晦涩的,用图说明是这样容易的(以下用腾讯文档制图)
这是1-10的正常链表,如果我们需要查询6,查询次数为6次, 复杂度为O(n)

增加了一级索引之后,发现次数减少到了4, 复杂度为O(logn)(https://www.geeksforgeeks.org/skip-list/?ref=lbp)
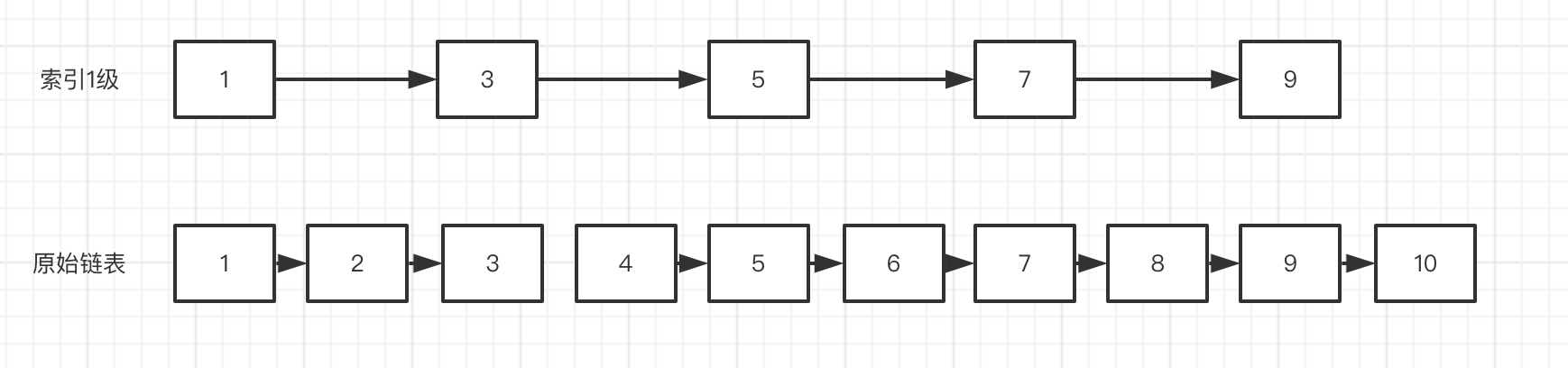
可以看出这是空间换时间的思想,增加n级索引的空间来置换查询效率,但是引起插入、删除的时间复杂度增加(相对原始单链表)
所以,考虑的场景应该是链表节点插入、更新少,查询频次多的情况。我们常用的redis有序集合就应用到了跳表。
接下来,我们使用MauriceGit/skiplist来操作跳表基础操作
import (
"fmt"
sl "github.com/MauriceGit/skiplist"
)
type Element int
// Implement the interface used in skiplist
func (e Element) ExtractKey() float64 {
return float64(e)
}
func (e Element) String() string {
return fmt.Sprintf("%d", e)
}
func main() {
list := sl.New()
// 插入1-20形成一跳表
for i := 1; i <= 20; i++ {
list.Insert(Element(i))
}
// 查询节点
if e, ok := list.Find(Element(11)); ok {
fmt.Println(e)
}
// 查询跳表最大值
lastValue := list.GetLargestNode().GetValue()
fmt.Println(lastValue)
}|
Function |
时间复杂度 |
|---|---|
|
Find |
O(log(n)) |
|
Insert |
O(log(n)) |
|
Delete |
O(log(n)) |
|
GetSmallestNode |
O(1) |
|
GetLargestNode |
O(1) |
正文完