

微博视频平台在4亿月活用户吃瓜嗨聊的高并发、大流量背景下,既要保证用户微博生产和消费体验,又要支持业务快速迭代,确保正确性、稳定性和高可用性。本次演将以微博视频大规模视频离线处理系统的架构设计为主题为大家带来大规模分布式系统的架构设计,性能优化和高可用保障等一线实战经验。
文 / 霍东海
整理 / LiveVideoStack
大家好,我是来自新浪微博视频平台和微博平台研发部的架构师霍东海,从2017年加入微博,目前在微博视频平台负责微博视频离线处理系统架构等相关工作,包括大规模离线微服务系统的架构设计和服务保障体系的建设等。近期专注于视频平台技术体系的提升对用户体验提升的帮助,主导构建了微博SVE(Streaming Video Engine)系统,支持大并发场景下对视频进行并行转码,大幅度提升转码效率。
1. 背景介绍


微博本身有大并发、大流量的特性,有4亿+的月活,同时微博也是一个开放平台,支持多种第三方分享,每天都会有百万视频分享需进行处理。
微博视频业务大概分两种业余形态,一个如左图所示,是竖版的短视频分享,另一个是如右图所示的稍微长一点的横向播放的短视频。
微博视频还有一些特殊的场景,例如在微博PC端点视频按钮会跳转到酷燃网,它是一个5到15分钟的短小综艺类视频分享的网站,如图中,下面都是一些优酷,爱奇艺,腾讯等视频网站分享到微博的视频。
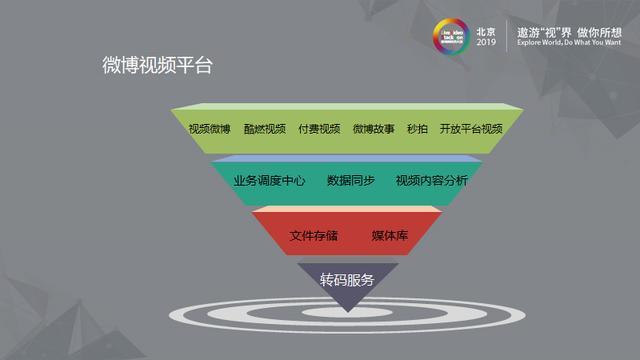
我们微博视频团队面临的业务场景是及其复杂的,我们要在复杂的场景下解决视频处理的问题。如图中,我们有微博视频,酷燃视频,付费视频,微博故事,秒拍,以及通过开放平台接入的视频分享网站,微博在最上层会接入极其多的业务方。中间会引入业务调度中心,即业务调度层,对上层业务进行调度。
另外是数据同步,所有的视频呈现在微博都是博文的形式,始终是需要和我们自己的系统进行交互的。业务调度层的另外一个作用就是对视频内容进行分析。往下一层是文件存储,媒体库层。文件存储包括文件上传,文件存储方面等的问题。媒体库是视频对象的源信息,如视频分辨率URL,视频长宽,用户ID,博文内容等信息存储。最下层是转码服务。我们重点介绍的就是转码服务在微博场景下的思考。
2. 微博视频转码服务架构与挑战
2.1 视频处理系统传统架构
在讲微博面临的问题之前,先来了解一下视频处理系统的传统架构。例如,某一用户在PC端或手机端有一个1080p,5Mbps的视频需要上传。在传统的架构中,会先将文件传到文件上传服务,文件上传服务将其传到底层存储。传到存储后,文件上传服务会告知转码服务文件需进行转码。转码时转码服务通过调度器将转码任务传到对应的转码集群中的转码服务器。真正转码的机器,从存储中下载用户上传的源文件,转换成特定格式后回存到存储中。
2.2 微博视频转码服务 – 业务繁杂
对微博视频而言,我们有非常繁杂的业务,例如业务方会有不同的水印,一些用户会对自己的视频有特殊要求,另外系统要能满足线上验证优化转码算法的需求,再加上转码服务本身会提供抽帧等基础服务,要使这些融合在一起快速方便的支持业务方的需求,我们面临很大的挑战。
2.3 微博视频转码服务 – 提速优化
另外,在优化视频基础体验的时候,我们会提出并行上传来提高用户上传成功率,做类似断点续传的功能,我们还会做并行转码完成云厂商提出的分片转码。甚至我们做到了用户边转边存,使视频在用户手机端完成分片,一边分片一边上传,上传的同时后台进行转码,上传完成的同时,转码即可完成,最后合并视频完成发送。这极大的提高了用户上传视频到发布微博这一过程的体验。
第一个是顺序上传。现在顺序上传的过程一般是二进制切片,切片后依次上传,整个系统延迟会比较长,做并行上传时,例如两个进程同时上传,会比顺序上传提速一倍。
在做并行转码时,相当于把视频做成二进制分片上传后,合并起来进行转码。转码时再将视频切分成不同时长的片段进行分片转码,完成后合并视频。这种方式下通过提高并行程度降低了延时。在边传边转方式下,客户端上传存储后,马上进行转码,客户端操作与服务端服务并行,最后服务端会将源视频、目标视频分别合并。
2.4 微博视频处理系统面临的挑战
我们面对业务繁杂,需进行基础服务优化的双重挑战。另外,微博业务具有很强的实时性,这就要求我们每环节都得快速完成,包括我们实现代码的时间,接入业务方上线的时间。我们必须实现一个低延时、高并发、高可用、高性能的视频转码服务。
视频转码服务本身需要大量计算,需要大规模的集群支持这项服务。我们面临的另外一个挑战就是对大量集群的管理。由于我们使用了分片转码,边传边转的优化方式,一个视频切成十片,转码量会变成十倍,这导致转码任务量陡增,同时也会产生一个更细粒度的调度。切片给我们带来更加复杂的任务依赖关系,我们要管理切片、分片并行转码以及合并整个过程中的任务依赖。过程中步骤越多,失败率越高,越要求系统有更高的健壮性降低失败。
我们今天主要讲的就是如何实现一个低延时、高并发、高可用、高性能的系统,我将主要从以下几个方面来说明。首先是高度灵活的配置生成系统,相当于将业务相关的东西从主系统中抽离放到配置系统中,使主系统专注于基础性能优化和基础服务。第二点要讲的是基于DAG的逻辑组织框架即用工作流引擎去组织任务之间的依赖。最后会讲一下高可用、高性能的任务调度器对系统的重要作用。
3. 微博视频转码服务架构设计
3.1 木林森
对于灵活配置,我们取名为木林森。它是一个基于树形结构的规则引擎,即我们的配置结果都是树形结构,多棵树即可组成森林,所以我们取名为木林森。木林森支持灵活的配置生成。微博有些业务场景下产品方只要求快速而不在意视频输出属性,这时我们可以直接使现有输出业务与输入业务连接完成业务接入。用这种方式可以提升新业务接入效率。下面是一个简单的示例。
如图,例如我们有微博原生视频接入业务,现在要接入的亿幕视频希望与原生视频有相同的输出。此时我们在输出业务以下到转码输出都不需要改变,我们只需要将节点连接,输入的亿幕视频就与微博原生视频有了相同的输出。只需通过后台点击配置就可将视频接入。右图所示是微博视频的输出配置。
复杂场景下,原生视频,秒拍视频,VIP视频的输出业务配置如图。不同用户端视频经过系统输出的视频是不同的。通过配置可完成复杂场景下的业务逻辑抽离。
3.2 DAG
我们自己实现了一套工作流引擎框架来支撑我们的业务,首先介绍一下框架的思想。我们是基于Java开发的,这里用Java举例。对于一般的上传系统,代码实现只有下载、转码、上传的过程。在这一段代码的基础上,我们要实现分片转码,边传边转等复杂的逻辑流。最简单的方法就是我们将一般上传的代码复制改动,这时我们的方式如右图。上传过程变为下载,切片,将切片结果上传,下载切片,切片转码,上传切片,然后使这个过程循环往复,这时可多台机器并行工作,最后将切片合并。由于过程复杂,所有我们希望能用有向无环图连接组织,将基础服务固化,通过脚本将不同功能组织起来。这时我们无论下载文件转码上传还是分片上传,只需简单连接即可,两个下载之间的代码是不需要改动的。我们将可固化的部分固化,将代码拆成一个个可独立执行的闭包,通过DAG管理包与包之间的关系,在DAG内部实现闭包的执行。这就是我们关于DAG框架的想法。
这是我们转码服务的图示。如图中,Center部分就是中央调度的服务,Runner部分是执行转码任务的服务,videoTrans是DAG组织任务间关系的脚本。我们的脚本通过Groovy实现。框架名字叫做Olympiadane,是通过Groovy引擎执行连成的关系,其中的Group是可独立调度的单位,即图中白色的部分。任务先经过调度器,调度器根据情况分发到执行器,执行器内部根据前后依赖关系顺序执行Task,在此例中就是下载,转码,上传。另一台机器也是一样的。这样就实现了执行流与业务之间的解耦,如果要接入其他的新服务的话,我们只需要再实现一个Task,将此Task的依赖关系放入脚本即可完成。另外通过脚本生成的就是图中的Job。这是我们DAG架构。
实现DAG框架后,可以通过脚本快速接入支持业务,由于脚本变动但Feature不是经常变动的,所以Feature可在脚本间共用,也可以独立测试,这样我们便可以完成可组装的独立组件。这些独立组件具备可以独立测试,易扩展,易部署,高性能的特性。
这里描述的是DAG的过程。前面我们提到的分片转码,过程分是下载,切片,上传分片结果几步。
例如有三个机器同时并行完成下载分片,转码,上传结果的工作。当并行过程结束后,会有一个新的依赖关系,如图中,下载所有分片,合并转码后的视频,不同清晰度的文件都是在不同机器上并行工作的。这是对我们转码服务优化中,通过DAG组织的一次实践。
如图中,灰色的部分变成了绿色,这表示这个过程是可以观测的,这也是通过DAG方式实现的一个优势。我们可以观测任务执行到了哪一步,也可以更快的定位出现问题的地方。另外,由于我们进行了拆分,可以对独立Feature进行DAG切面,例如我们可以统计它的耗时,这样我们可以知道哪种类型的业务耗时较长,也有助于观察系统的稳定性。
在DAG的优化方面,我们通过字节码编译技术做到了脚本快速执行。另外我们引入了一些Protostuff技术快速完成资源存储。
3.3 调度器
我们通过木林森将业务系统抽离出来,通过DAG系统将实现时的依赖关系抽离,因此我们需要一个好的调度系统来支撑。由于我们进行了切片,因此调度任务达到了万次每秒。我们也会需要更细粒度的调度任务,比起粗粒度的调度,对基础组件性能要求更高。我们对调度器的另外一个设计目标就是调度占比要低于百分之五,这就意味着系统损耗更低。这对调度器有极高要求,我们要使百分之九十九的调度任务在10ms内分派到对应机器,并且我们希望它的调度是最优调度,即能准确把任务分派到空闲机器。
在设计调度器时我们也做了一些思考。我们对中心化调度器和非中心化调度器做了对比。中心化调度器的调度准确度高,它将资源队列信息放到中心化存储中,对监控更亲和。但是它的资源依赖较多,我们将队列放到了资源中,因此资源访问读写中会产生一定依赖,也会有一定性能损耗。对于去中心化调度器来说,它的扩展性更强,但是它存在调度不准确的问题。最终我们选择了中心化调度方式。
上图是调度器调度过程。左边是调度器,右边是执行器。调度器和执行器之间通过心跳注册,心跳时间是可配置的。注册完后会将机器信息放到机器队列,中心资源中有一个任务优先级队列,我们可以对不同任务映射不同优先级。另外一个是机器空闲优先级队列,就是我们将机器空闲度映射为优先级。在派发时,我们会取到高优先级任务,取到空闲度优先级高的执行器,然后将任务派到指定机器,即可将任务放到执行队列中。执行队列的重要作用在后面会讲到。执行结束后,会进行一次回调,从执行队列中移除任务。我们通过三个队列完成任务调度,由于存在资源依赖,所以我们对这些资源进行了哈希计算,不同机器可以使用不同资源,只要资源满足就可分派任务。
但是这里会有一个问题。心跳会汇报情况,但它会有一定延迟,如果Executor与资源中存储的状态产生差异,任务可能会被分派到一台无法工作的机器。为解决此问题,我们设计了一个带锁的双发调度。与之前介绍的相同,我们依然从队列选择机器。不同的是,我们会在空闲优先级队列中取到最优的同时,取一个随机机器去完成分派。分派后,执行器会再一次调用调度器确认由谁完成任务,再去执行。当最优任务不可执行时,另外一个机器可完成任务。这样,我们就可以实现百分之九十九的任务在10毫秒内完成分派的目的。同样的,带锁双发调度也会有哈希计算的存在。同时,我们会使用WatchDog观察执行队列中的任务是否在规定时间完成,若没有完成,我们会重新触发调度器分派任务。这样我们可以有效减慢失败率提升。
通过以上设计,我们的调度器可以实现毫秒级派发。对于微博业务来说,可能会出现紧急大流量出现,我们在设计时也考虑了水平伸缩方式,使它支持弹性扩缩容。通过WatchDog机制,我们可以实现宕机自动摘除。在实际应用中,我们每天都会有机器扩缩容,我们的做法是让待扩容机器不接受任务,先完成已有任务,再做机器扩缩容工作。但这样做还会有未完成的任务存在,通过WatchDog机制,我们可以确保这些任务重新分派完成。同时我们实现了4个9可用性。
3.4 部署
在转码服务部署方面,我们在两个IDC部署了完全相同的两套资源,它们有独立的域名,独立的部署。这么做的好处是我们可以在两个机房间随意的切流量,任一机房出现问题,我们都可以切换,但是两个机房的部署并不是一比一的冗余。我们常备的机房是一个大规模集群,另一个机房是一个小规模的,或许只有常备机房十分之一的量。两个机房在使用时可以分开,例如我们转一些不影响用户发博的转码输出时,可以使用小机房完成任务,这样大机房出现“灾难性”情况时,可以把流量切到小机房。当然小机房是不能满足那么大流量的,但是调度器本身的队列有堆积的特性,可以将堆积的任务慢慢执行。没有大量机器冗余可以充分利用机器。
4. 总结
接下来,我将所有内容做一个总结。通过转码服务的优化提升,我们整体转码提速了5倍,集群利用率标准差下降了百分之五十。这里的标准差指由于分派任务不合理,分到不同清闲度的任务导致机器CPU利用率忽高忽低的情况。通过好的调度方式,对集群的利用率标准差有很大降低。另外,我们业务支撑的效率也成倍提升。我们通过各种方式进行解耦,将变化大的和变化小的分开放到不同位置。
在服务架构设计开发的过程中,我们使用了很多并行手段,包括机器并行、进程并行、线程的并行以及算法、CPU核的并行等,通过这些手段发挥机器最大的价值。今天我们设计的目的是一个低延时高可用的系统,我们用到的并行上传,并行转码,极致上传等手段都用了算法上分治、递归、贪心的思想。在高可用方面使用了高内聚低耦合的思想,用到了动静分离、自动容错、异地多活的手段。最后想和大家分享,我们在做系统架构、设计优化不知道该如何实现的时候,就可以无脑的把这些高内聚低耦合、空间换时间等常见的思想往系统上套,或许就可以得到想要的结果。优化架构并不是多么复杂深奥的东西,我们要去思考的是前人总结的这些手段在我们自己系统上的能否达到效果,如果得到了满意的效果,那么这些思想就会转化为我们自己的东西。