很多小伙伴,可能在使用SCF的时候,需要做一些深度学习的操作,但是SCF能跑起来深度学习么?这是个问题!那么,我们就尝试一下,看看如何让SCF跑起来深度学习!
有一张图:

需要用深度学习相关知识,识别出图的内容:
我们在本地已经训练好了模型,同时可以安装以下依赖:
pip3 install numpy scipy opencv-python pillow matplotlib h5py keras -t /Users/dfounderliu/Documents/code/imageaidemopip3 install https://github.com/OlafenwaMoses/ImageAI/releases/download/2.0.1/imageai-2.0.1-py3-none-any.whl -t /Users/dfounderliu/Documents/code/imageaidemo注意一下,这个安装中-t后面的参数实际上是我们项目目录。
安装之后,可以下载两个训练好的模型文件:
https://mytest-1256773370.cos.ap-beijing.myqcloud.com/resnet50_coco_best_v2.0.1.h5
https://mytest-1256773370.cos.ap-beijing.myqcloud.com/resnet50_weights_tf_dim_ordering_tf_kernels.h5
这两个模型文件下载好了之后,我们可以实现代码:
# -*- coding: utf-8 -*-
from imageai.Prediction import ImagePrediction
from imageai.Detection import ObjectDetection
import os
import base64
import json
import hashlib
import PIL.Image as image
import imghdr
class ImageHandle:
# 等比例压缩图片
def resizeImg(self, **args):
# try:
args_key = {'ori_img': '', 'dst_img': '', 'dst_w': '', 'dst_h': '', 'save_q': 75}
arg = {}
for key in args_key:
if key in args:
arg[key] = args[key]
im = image.open(arg['ori_img'])
ori_w, ori_h = im.size
widthRatio = heightRatio = None
ratio = 1
if (ori_w and ori_w > arg['dst_w']) or (ori_h and ori_h > arg['dst_h']):
if arg['dst_w'] and ori_w > arg['dst_w']:
widthRatio = float(arg['dst_w']) / ori_w # 正确获取小数的方式
if arg['dst_h'] and ori_h > arg['dst_h']:
heightRatio = float(arg['dst_h']) / ori_h
if widthRatio and heightRatio:
if widthRatio < heightRatio:
ratio = widthRatio
else:
ratio = heightRatio
if widthRatio and not heightRatio:
ratio = widthRatio
if heightRatio and not widthRatio:
ratio = heightRatio
newWidth = int(ori_w * ratio)
newHeight = int(ori_h * ratio)
else:
newWidth = ori_w
newHeight = ori_h
im.resize((newWidth, newHeight), image.ANTIALIAS).save(arg['dst_img'], quality=arg['save_q'])
'''
image.ANTIALIAS还有如下值:
NEAREST: use nearest neighbour
BILINEAR: linear interpolation in a 2x2 environment
BICUBIC:cubic spline interpolation in a 4x4 environment
ANTIALIAS:best down-sizing filter
'''
# except Exception as e:
# errorLogger(e)
def getExecutionPath(self):
return os.getcwd()
def getMd5(self, strData):
m = hashlib.md5()
m.update(strData)
return m.hexdigest()
def imagePrediction(self, pathInputData):
self.type = imghdr.what(pathInputData)
if self.type == "jpeg":
self.type = "jpg"
if self.type not in ["jpg", "png"]:
return None
tempData = pathInputData[0:-4]
pathData = tempData + ".jpg"
zhuanhuanPic = tempData + "zh." + self.type
# 目标图片大小
dst_w = 400
dst_h = 0
# #保存的图片质量
save_q = 40
# 等比例压缩
try:
img = image.open(pathInputData)
bg = image.new("RGB", img.size, (255, 255, 255))
bg.paste(img, img)
bg.save(pathInputData)
except:
pass
self.resizeImg(ori_img=pathData, dst_img=zhuanhuanPic, dst_w=dst_w, dst_h=dst_h, save_q=save_q)
prediction = ImagePrediction()
prediction.setModelTypeAsResNet()
prediction.setModelPath(os.path.join(self.getExecutionPath(), os.path.join(self.getExecutionPath(),
"tools/imageAI/resnet50_weights_tf_dim_ordering_tf_kernels.h5")))
prediction.loadModel()
predictions, probabilities = prediction.predictImage(os.path.join(self.getExecutionPath(), zhuanhuanPic),
result_count=5)
result = []
for eachPrediction, eachProbability in zip(predictions, probabilities):
result.append(eachPrediction + " : " + eachProbability)
return json.dumps(result)
def objectDetection(self, pathInputData):
self.type = imghdr.what(pathInputData)
if self.type == "jpeg":
self.type = "jpg"
if self.type not in ["jpg", "png"]:
return None
tempData = pathInputData[0:-4]
pathOutputData = tempData + "out." + self.type
zhuanhuanPic = tempData + "zh." + self.type
# 目标图片大小
dst_w = 400
dst_h = 0
# #保存的图片质量
save_q = 40
# 等比例压缩
try:
img = image.open(pathInputData)
bg = image.new("RGB", img.size, (255, 255, 255))
bg.paste(img, img)
bg.save(pathInputData)
except:
pass
self.resizeImg(ori_img=pathInputData, dst_img=zhuanhuanPic, dst_w=dst_w, dst_h=dst_h, save_q=save_q)
try:
detector = ObjectDetection()
detector.setModelTypeAsRetinaNet()
detector.setModelPath(os.path.join(self.getExecutionPath(), "resnet50_coco_best_v2.0.1.h5"))
detector.loadModel()
detections = detector.detectObjectsFromImage(input_image=zhuanhuanPic, output_image_path=pathOutputData)
with open(pathOutputData, "rb") as f:
# b64encode是编码,b64decode是解码
base64_data = base64.b64encode(f.read()).decode("utf-8")
result = []
for eachObject in detections:
result.append(eachObject["name"] + " : " + eachObject["percentage_probability"])
return json.dumps({
"information": base64_data,
"result": result})
except Exception as e:
return json.dumps({
"information": str(e),
"result": "error"})
imageData = ImageHandle()
result = imageData.objectDetection('1.png')
print(result)
这里面要注意修改你的目标图片名字以及刚才下载的文件存存放路径。
我们可以测试一个图像:
接下来,我们可以看一下文件压缩大小(北京区自带Tensorflow,所以压缩时候不考虑Tensorflow):
可以看到,代码+依赖的大小已经超过上传的50Mzip限制,所以,我们可以在北京区开一个对象存储,然后将我们的代码和训练好的模型上传:
然后我们在北京区,新建一个云函数:
建立之后,我们还要修改内存和超时时间:
然后,我们还需要对index.py进行简单的改造,让其符合云函数的规则:
# -*- coding: utf-8 -*-
from imageai.Prediction import ImagePrediction
from imageai.Detection import ObjectDetection
import urllib.parse
import os
import base64
import json
import hashlib
import PIL.Image as image
import imghdr
from qcloud_cos_v5 import CosConfig
from qcloud_cos_v5 import CosS3Client
from qcloud_cos_v5 import CosServiceError
from qcloud_cos_v5 import CosClientError
class ImageHandle:
# 等比例压缩图片
def resizeImg(self, **args):
# try:
args_key = {'ori_img': '', 'dst_img': '', 'dst_w': '', 'dst_h': '', 'save_q': 75}
arg = {}
for key in args_key:
if key in args:
arg[key] = args[key]
im = image.open(arg['ori_img'])
ori_w, ori_h = im.size
widthRatio = heightRatio = None
ratio = 1
if (ori_w and ori_w > arg['dst_w']) or (ori_h and ori_h > arg['dst_h']):
if arg['dst_w'] and ori_w > arg['dst_w']:
widthRatio = float(arg['dst_w']) / ori_w # 正确获取小数的方式
if arg['dst_h'] and ori_h > arg['dst_h']:
heightRatio = float(arg['dst_h']) / ori_h
if widthRatio and heightRatio:
if widthRatio < heightRatio:
ratio = widthRatio
else:
ratio = heightRatio
if widthRatio and not heightRatio:
ratio = widthRatio
if heightRatio and not widthRatio:
ratio = heightRatio
newWidth = int(ori_w * ratio)
newHeight = int(ori_h * ratio)
else:
newWidth = ori_w
newHeight = ori_h
im.resize((newWidth, newHeight), image.ANTIALIAS).save(arg['dst_img'], quality=arg['save_q'])
'''
image.ANTIALIAS还有如下值:
NEAREST: use nearest neighbour
BILINEAR: linear interpolation in a 2x2 environment
BICUBIC:cubic spline interpolation in a 4x4 environment
ANTIALIAS:best down-sizing filter
'''
# except Exception as e:
# errorLogger(e)
def getExecutionPath(self):
return os.getcwd()
def getMd5(self, strData):
m = hashlib.md5()
m.update(strData)
return m.hexdigest()
def imagePrediction(self, pathInputData):
self.type = imghdr.what(pathInputData)
if self.type == "jpeg":
self.type = "jpg"
if self.type not in ["jpg", "png"]:
return None
tempData = pathInputData[0:-4]
pathData = tempData + ".jpg"
zhuanhuanPic = tempData + "zh." + self.type
# 目标图片大小
dst_w = 400
dst_h = 0
# #保存的图片质量
save_q = 40
# 等比例压缩
try:
img = image.open(pathInputData)
bg = image.new("RGB", img.size, (255, 255, 255))
bg.paste(img, img)
bg.save(pathInputData)
except:
pass
self.resizeImg(ori_img=pathData, dst_img=zhuanhuanPic, dst_w=dst_w, dst_h=dst_h, save_q=save_q)
prediction = ImagePrediction()
prediction.setModelTypeAsResNet()
prediction.setModelPath(os.path.join(self.getExecutionPath(), os.path.join(self.getExecutionPath(),
"tools/imageAI/resnet50_weights_tf_dim_ordering_tf_kernels.h5")))
prediction.loadModel()
predictions, probabilities = prediction.predictImage(os.path.join(self.getExecutionPath(), zhuanhuanPic),
result_count=5)
result = []
for eachPrediction, eachProbability in zip(predictions, probabilities):
result.append(eachPrediction + " : " + eachProbability)
return json.dumps(result)
def objectDetection(self, pathInputData):
self.type = imghdr.what(pathInputData)
if self.type == "jpeg":
self.type = "jpg"
if self.type not in ["jpg", "png"]:
return None
tempData = pathInputData[0:-4]
pathOutputData = tempData + "out." + self.type
zhuanhuanPic = tempData + "zh." + self.type
# 目标图片大小
dst_w = 400
dst_h = 0
# #保存的图片质量
save_q = 40
# 等比例压缩
try:
img = image.open(pathInputData)
bg = image.new("RGB", img.size, (255, 255, 255))
bg.paste(img, img)
bg.save(pathInputData)
except:
pass
self.resizeImg(ori_img=pathInputData, dst_img=zhuanhuanPic, dst_w=dst_w, dst_h=dst_h, save_q=save_q)
try:
detector = ObjectDetection()
detector.setModelTypeAsRetinaNet()
detector.setModelPath(os.path.join(self.getExecutionPath(), "/tmp/resnet50_coco_best_v2.0.1.h5"))
detector.loadModel()
detections = detector.detectObjectsFromImage(input_image=zhuanhuanPic, output_image_path=pathOutputData)
with open(pathOutputData, "rb") as f:
# b64encode是编码,b64decode是解码
base64_data = base64.b64encode(f.read()).decode("utf-8")
result = []
for eachObject in detections:
result.append(eachObject["name"] + " : " + eachObject["percentage_probability"])
return json.dumps({
"information": base64_data,
"result": result})
except Exception as e:
return json.dumps({
"information": str(e),
"result": "error"})
def save_picture(base64data):
print("保存图像")
try:
imgdata = base64.b64decode(urllib.parse.unquote(base64data))
file = open('/tmp/picture.png', 'wb')
file.write(imgdata)
file.close()
return True
except Exception as e:
return str(e)
def ana_picture():
print("目标检测")
imageData = ImageHandle()
result = imageData.objectDetection('/tmp/picture.png')
return result
def main_handler(event, context):
print("下载h5文件")
secret_id = "secretid"
secret_key = "secretkey"
region = u'ap-beijing' # 请替换为您bucket 所在的地域
config = CosConfig(Secret_id=secret_id, Secret_key=secret_key, Region=region)
client = CosS3Client(config)
response = client.get_object(Bucket='mytest-1256773370', Key='resnet50_coco_best_v2.0.1.h5', )
response['Body'].get_stream_to_file('/tmp/resnet50_coco_best_v2.0.1.h5')
response = client.get_object(Bucket='mytest-1256773370', Key='resnet50_weights_tf_dim_ordering_tf_kernels.h5', )
response['Body'].get_stream_to_file('/tmp/resnet50_weights_tf_dim_ordering_tf_kernels.h5')
print("开始预测")
save_result = save_picture(event["body"].replace("image=",""))
if save_result == True:
return ana_picture()
else:
return save_result
然后我们点击测试运行,可以看到程序执行正确,返回了我们的结果base64编码:
额外说明:如果自己在自己电脑下载的依赖,然后上传到云函数报错,可以考虑使用http://139.155.143.138:8080/?name=matplotlib&version=3.1.0来进行包下载,该工具是自己开发的,仅供学习测试使用,内部系统是CentOS+Python3.6。使用方法可以参考:https://cloud.tencent.com/developer/article/1443375
至此,我们完成了一个目标检测的小Demo,接下来,我们通过API网关设置触发器:
接下来发布到测试环境中:
接下来编写本地的测试脚本:
import base64
import urllib.request
import urllib.parse
with open("1zh.png","rb") as f:
base64_data = base64.b64encode(f.read()) # 使用base64进行加密
url = "http://service-ajhz9o1z-1256773370.ap-beijing.apigateway.myqcloud.com/test/picture"
data = {
"image": base64_data.decode("utf-8")
}
print(urllib.parse.unquote(urllib.request.urlopen(urllib.request.Request(url, data=urllib.parse.urlencode(data).encode("utf-8"))).read().decode("utf-8")))
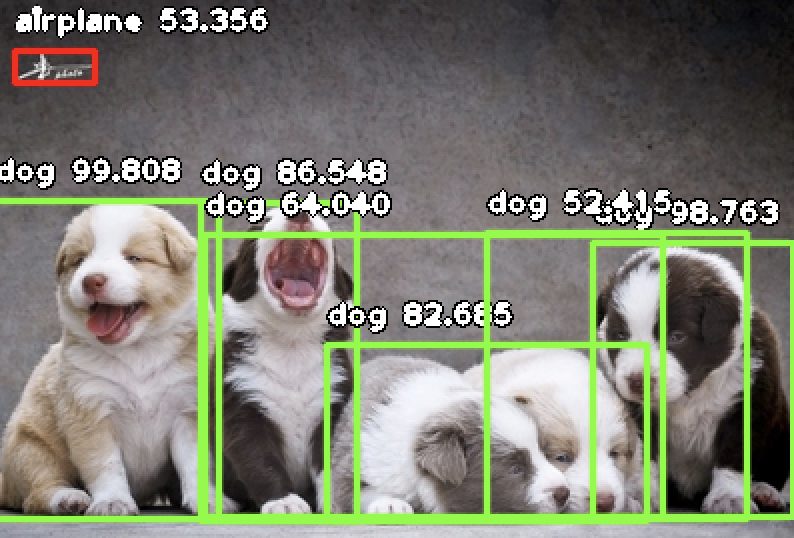
原图:
结果:
本文主要点:
1: 超过50M的代码应该如何上传云函数
2: 云函数中是否可以进行深度学习相关的操作(本文是预测,使用了Tensorflow)
代码下载地址:https://mytest-1256773370.cos.ap-beijing.myqcloud.com/index.zip