一、概述
目前公司离线数仓现状,数仓部门每日凌晨后处理昨天的线上业务数据,因此第二天业务人员才看到的报表,数据是T-1的,因此数据是具有滞后性,尤其在互联网金融公司,有业务人员需要做信贷的风险管控,及时的调整一些风控规则和策略,但是不能立刻看到效果,而是需要等到第二天才可以看到调整的效果,因此才有了实时数仓的需求。线上业务数据基本存储在Mysql和MongoDB数据库中,因此实时数仓会基于这两个工作流实现,本文重点讲述基于MongoDB实现实时数仓的架构。
由于线上MongoDB是Sharding模式,规模中等,但由于数据量比较大,因此集群的IO一直存储高负荷状态,无法开放查询功能给业务人员进行实时查询。期间由于一个业务部分查询条件Key值有误造成全库扫描(COLLSCAN),造成在业务出现很多Slow-Query,因此线上集群不再提供个人查询需求,基于目前现状,有我们基础架构部调研并基于MongoDB实现的实时数仓的技术方案。
二、实现的具体步骤
2.1 架构图
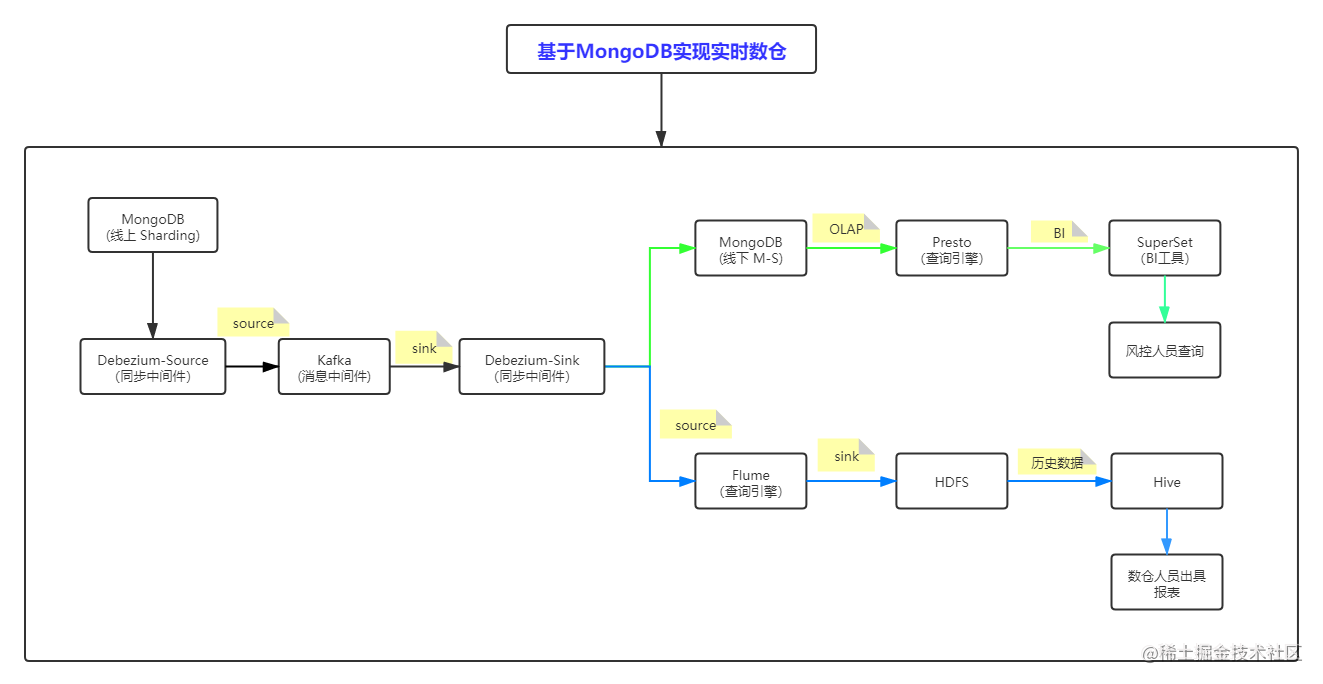
- a) 架构图中”绿色”线条是提供风控业务人员实时查询策略效果的流程图,由于服务器资源有限,因此从上线MongoDB-Sharding实时同步到线下MongoDB—RS(副本),因此不可能保存全部数据,而且对保存数据的有效期也有限制,在实现前期规划中实时数据默认保留14天(在线下mongodb库中对数据表需要增加过期索引)
- b) 架构图中”蓝色”线条是提供给实时数仓,并且保留历史数据。
2.2 Debezium CDC实现过程
mongodb同步工具:mongo-kafka 官方提供的jar包,具备Source、Sink功能,但是不支持CDC。无法从上线MongoDB库同步到线下MongoDB库,最初选择Confluent工具是由于它集成了多个同步组件,是目前比较流行的同步工具,同时是一个可靠的,高性能的流处理平台。但是由于MongoDB同步需求的改变,需要选择一种支持CDC的同步工具-Debezium。
Debezium-MongoDB连接器可以监视MongoDB副本集或MongoDB分片群集中数据库和集合中的文档更改,并将这些更改记录为Kafka主题中的事件。连接器自动处理分片群集中分片的添加或删除,每个副本集的成员资格更改,每个副本集内的选举以及等待通信问题的解决。
目前选择方案: 使用Debezium Souce 同步mongo数据进入Kafka, 然后使用Mongo-Kafka Sink功能同步Kafka 数据到线下MongoDB库。这样既可以解决数仓实时读取Kafka,又能解决政审部门查询线下MongoDB库的问题。
2.2.1 工具集成
1) 下载源码
地址:https://github.com/debezium/debezium/archive/v0.10.0.Final.tar.gz
2) 业务需求
在每条update/delete数据记录中增加oid标识,以提供数仓溯源使用。
3) 实现方法
打开debezium/RecordMakers.java::createRecords() 中增加value.put("objectid", objId);
4) 编译
命令:mvn install -pl debezium-connector-mongodb -Ddocker.skip.build=true -Ddocker.skip.run=true -DskipITs=true
5) 构建新docker镜像
将编译后的包:debezium-connector-mongodb/target/debezium-connector-mongodb-0.10.0.Final.jar 拷贝到debezium/connect:0.10 Docker容器内。重新commit、push到测试环境。
6) 打包Sink功能
将Mongo-Kafka 编译后的jar包(mongo-kafka-0.3-SNAPSHOT-all.jar) 拷贝到debezium/connect:0.10 Docker容器内/kafka/connect/mongodb-kafka-connect目录下。需要提前创建mongodb-kafka-connect目录。 重新commit、push image到测试环境。
7) 容器内目录结构
[kafka@deb-connect ~]$ ls -l connect/
total 8
drwxr-xr-x 1 kafka kafka 52 Dec 1 16:18 debezium-connector-mongodb
drwxr-xr-x 1 kafka kafka 4096 Oct 2 00:52 debezium-connector-mysql
drwxr-xr-x 1 kafka kafka 204 Oct 2 00:52 debezium-connector-oracle
drwxr-xr-x 1 kafka kafka 285 Oct 2 00:52 debezium-connector-postgres
drwxr-xr-x 1 kafka kafka 259 Oct 2 00:52 debezium-connector-sqlserver
drwxrwxr-x 1 kafka kafka 46 Nov 28 08:27 mongodb-kafka-connect
复制代码2.2.2 Debezium上线部署
# 由于需要提供Source和Sink功能,根据同步库的数量,适当的增加Docker数量,这样可以确保任务的正常高效执行。根据相同的GROUP_ID为一个集群,支持负载均衡。默认数据格式为:Avro。
# 依赖的环境变量如下:
GROUP_ID: "DW-MongoToKafka"
KAFKA_HEAP_OPTS: "-Xms2G -Xmx8G"
SERVICE_28083_NAME: "dw-mongo-connect"
SANITIZE_FIELD_NAMES: "true"
CONNECT_PRODUCER_MAX_REQUEST_SIZE: 16777216
KAFKA_PRODUCER_MAX_REQUEST_SIZE: 16777216
STATUS_STORAGE_TOPIC: "debezium_connect_status"
CONFIG_STORAGE_TOPIC: "debezium_connect_configs"
OFFSET_STORAGE_TOPIC: "debezium_connect_offsets"
KEY_CONVERTER: "io.confluent.connect.avro.AvroConverter"
VALUE_CONVERTER: "io.confluent.connect.avro.AvroConverter"
INTERNAL_KEY_CONVERTER: "org.apache.kafka.connect.json.JsonConverter"
INTERNAL_VALUE_CONVERTER: "org.apache.kafka.connect.json.JsonConverter"
CONNECT_KEY_CONVERTER_SCHEMA_REGISTRY_URL: "http://dw-schema-registry.com"
CONNECT_VALUE_CONVERTER_SCHEMA_REGISTRY_URL: "http://dw-schema-registry.com"
BOOTSTRAP_SERVERS: "dn5.infra.app:9092, dn6.infra.app:9092, dn7.infra.app:9092"
复制代码2.2.3 创建Source connector
# 使用API方式创建source connector,开启实时同步MongoDB-Sharding数据到Kafka Topic
curl -X POST -H "Content-Type: application/json" --data
'{
"name": "debezium-source-表名",
"config": {
"connector.class":"io.debezium.connector.mongodb.MongoDbConnector",
"sanitize.field.names":"true",
"tasks.max":"1",
"mongodb.hosts":"mongos地址:端口",
"mongodb.user":"用户名",
"mongodb.password":"密码",
"mongodb.name":"datawarehouse.mongo.debezium",
"database.whitelist":"库名",
"collection.whitelist":"库名.表名",
"max.request.size":"16777216",
"database.history.kafka.bootstrap.servers":"dn5.infra.app:9092"
}
}' http://dw-mongo-connect.com/connectors/
复制代码2.2.4 创建Sink Connector
# 使用API方式创建sink connector,开启实时增量同步Kafka数据到线下MongoDB-RS库。
curl -X POST -H "Content-Type: application/json" --data
'{
"name": "debezium-sink-表名",
"config": {
"tasks.max":"1",
"database":"目标库",
"topics":"填写source connector同步的topic",
"connection.uri":"mongodb://用户名:密码@IP:PORT/库名",
"collection":"表名",
"connector.class":"com.mongodb.kafka.connect.MongoSinkConnector",
"change.data.capture.handler":"com.mongodb.kafka.connect.sink.cdc.debezium.mongodb.MongoDbHandler"
}
}' http://dw-mongo-connect.com/connectors/
复制代码2.2.5 Topic 数据保留时效
# 由于kafka服务器存储受限,根据业务数据需求修改topic 保留失效为3天
kafka-topics --zookeeper zk地址:2181 --alter --topic TopicName --config retention.ms=259200000
复制代码2.2.6 检查Debezium同步数据效果
A) 查看Prometheus kafka 监控的Dashboard
B) 查看线下MongoDB-RS库下的数据
2.2.7 问题&记录
# 由于线上Mongo-Sharding集群对DataBase都有严格的权限管理,因此在创建connector后,一般会出现权限拒绝问题。错误信息如下
【2019-11-30 16:49:52,955 ERROR MongoDB|datawarehouse.mongo.debezium|confrs Error while attempting to get oplog position: Exception authenticating MongoCredential{mechanism=SCRAM-SHA-1, userName='同步用户', source='admin', password=<hidden>, mechanismProperties={}} [io.debezium.connector.mongodb.Replicator]
com.mongodb.MongoSecurityException: Exception authenticating MongoCredential{mechanism=SCRAM-SHA-1, userName='同步用户', source='admin', password=<hidden>, mechanismProperties={}}】
使用Debezium Source connector 同步Mongo-sharding数据时,需要开启的权限为: mongos进入后admin库的read权限
mongos> show users;
{
"_id" : "admin.同步用户",
"userId" : UUID("fb982511-c779-41b8-8a9f-9ba492c30c28"),
"user" : "同步用户",
"db" : "admin",
"roles" : [
{
"role" : "read",
"db" : "risk"
},
{
"role" : "read",
"db" : "admin"
},
{
"role" : "read",
"db" : "config"
}
],
"mechanisms" : [
"SCRAM-SHA-1",
"SCRAM-SHA-256"
]
}
进入每个Replica下,创建 admin和local库的 read权限。
s5rs:PRIMARY> show users;
{
"_id" : "admin.同步用户",
"userId" : UUID("b99bd150-dc9c-4f67-8177-2580b78d63c1"),
"user" : "同步用户",
"db" : "admin",
"roles" : [
{
"role" : "read",
"db" : "local"
},
{
"role" : "read",
"db" : "admin"
}
],
"mechanisms" : [
"SCRAM-SHA-1",
"SCRAM-SHA-256"
]
}
使用Mongo-Kakfa Sink connector操作线下Mongodb时,需要开启权限:
riskPoolRs:PRIMARY> show users;
{
"_id" : "risk.同步用户",
"userId" : UUID("9f5e079f-a665-4664-830f-8b54f9848ea2"),
"user" : "同步用户",
"db" : "库名",
"roles" : [
{
"role" : "readWrite",
"db" : "risk"
},
{
"role" : "read",
"db" : "admin"
},
{
"role" : "clusterAdmin",
"db" : "admin"
}
],
"mechanisms" : [
"SCRAM-SHA-1",
"SCRAM-SHA-256"
]
}
复制代码默认情况下debezium source connector 同步数据大小限制1M以内。 同步mongo大数据时需要修改此参数。”max.request.size”:”16777216″ 修改为16M
2.3 对接Presto
这个步骤比较简单,根据presto官方提供的配置说明
2.3.1 增加配置文件
# 在etc/catalog下创建mongodb.properties
connector.name=mongodb
mongodb.seeds=IP:27017
mongodb.credentials=用户名:密码@库名
mongodb.schema-collection=presto_mongo
mongodb.socket-keep-alive=true
复制代码2.3.2 重启presto
bin/launcher stop
bin/launcher start
复制代码2.3.3 问题&记录
问题:presto 连接mongo读取数据时,发现没有显示所有的字段?? 解决:在mongo库中查询schema数据,发现缺少某些字段值,登陆mongo手动更新schema数据,增加指定域值的显示,定义为varchar类型。 修改之前
修改之后
2.4 对接SuperSet
打开superset界面,选择添加数据源
打开SQL编辑器,即可进行实时查询mongo数据
三、准实时报表
结构图的”蓝色”线条 实现过程比较简单基于Flume对接Kafka写入Hive这个是数仓平台上的一个定时任务,实现比较简单,数据是实时同步的, 但是基于数仓的特性,不能做到分钟级别的报表,但是可以做到小时级别的。如果需要准实时报表,则需要基于Druid或Kylin等分析引擎处理数据,这个方案会在后面博文中介绍。
四、总结
在mongodb实时数仓架构实现过程中,由于环境不同,在部署过程中会遇到不少问题, 但是不要怕,正是因为这些问题才让你更深入的了解各个模块内部实现原理和机制,耐心一点,总会解决的。 另外,上述的基于MongoDB实现的实时数仓架构并不是最优的,主要是结合公司目前业务架构以及各个系统、网络等环境的限制,调研的实时方案。