当下,随着数字化技术不断深入,愈来愈多企业将核心业务搬到线上。业务系统高可用、可扩展、容灾能力决定企业系统的连续性,中间件作为构建企业核心系统的重要组成部分,其高可用容灾能力也将决定应用系统的。本文结合腾讯云中间件各PaaS产品的容灾能力及实践,以一个行业头部客户业务容灾实践举例,来展开说明基于腾讯云中间件PaaS层相关产品的实践。
下面就分别对Ckafka、ES、Redis云产品在客户业务容灾场景中的相关案例。
Ckafka的容灾能力可以分为:跨可用区容灾及跨地域级容灾。
Ckafka跨可用区容灾
跨可用区容灾:指的是在同一个地域内部,一个Ckafka集群节点跨可用区部署,作为一个大集群。这个跨可用区部署大集群的方式是原生kafka所推荐支持的。可以大幅度提升集群的容灾能力,当单个可用区出现意外的网络不稳定、断电重启等不可抗力风险 时,仍能保证客户端在短时间等待重连后恢复消息的生产和消费。
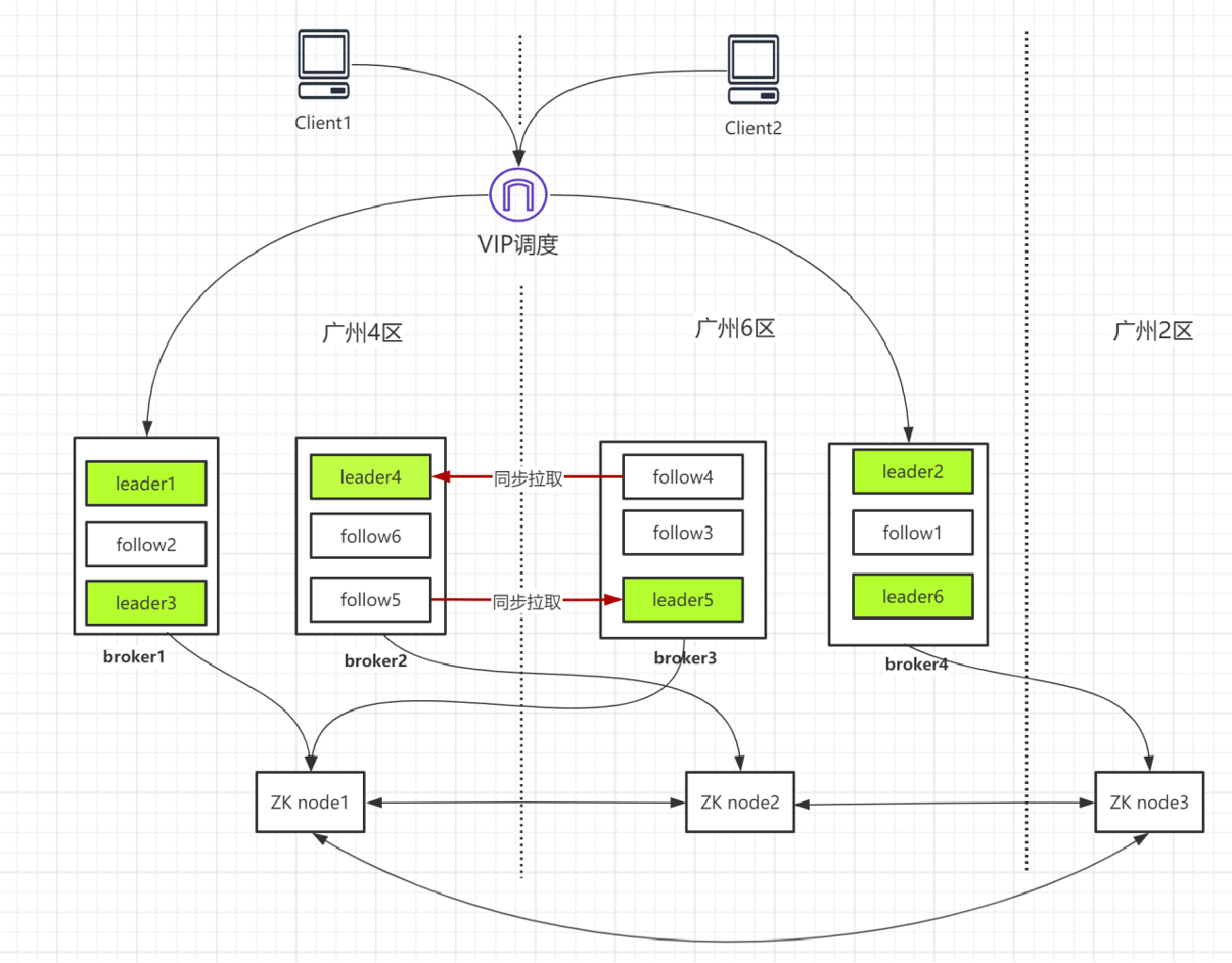
部署说明说明
Ckafka跨可用区集群:采用Ckafka 专享版,实例采用4个broker节点,跨2个可用区部署(广州4区与广州6区各2个broker节点)。
实例规格建议:峰值带宽:1000MB/s,Partition规格:2800个。
ZK集群:3个节点跨3个可用区部署。广州4区与6区各一个,另外在广州2区也部署一个,组成一个集群。
高可用说明:
- 采用VIP接入, 实现跨可用区(AZ)访问能力,具有故障漂移能力。当4区与6区网络出现中断后,部署在4区 的应用可访问6区broker节点。
- 当4、6区任意一个可用区出现故障: 触发Ckafka实例各分区leader切换,实现所有leader分区从故障节点转移到正常可用区。 客户端应用可以通过VIP从正常可用区节点请求Ckafka实例正常的broker节点。
- 当4、6区之间网络抖动、断开(60s)之后:通过VIP切换,客户端都能够正常的进行消息生产和消费,影响对业务无感知。不影响整个集群间broker上报到ZK集群,整个实例集群正常运行。 会影响到4、6区之间分区leader节点与follow节点间数同步,当网络恢复正常之后,继续进行leader与follow数据同步。
- 在4、6区之间网络出现抖动/断连之后,4区又出现故障,触发Ckafka的leader切换,原来的follow节点提升leader节点,因为之前数据同步延迟,可能会造成部分数据丢失。根据分布式CAP原则,需要在可用性与数据一致性作出权衡。 数据一致性优先:通过设置ack=all,可以保证在4、6区出现网络中断后,确保leader与follow节点数据一致,但是会造成因为断连导致数据写入失败,需要重试。 可用性优先:设置ack = 1,只需要leader节点写入成功。当4、6区网络异常,对正常写入无影响。但是会在一段时间内数据丢失。这里服务端可以通过优化follow与leader同步优化,客户端重试最大限度减少数据丢失量级。
Ckafka跨地域热备容灾
跨地域容灾指的是分别部署2套Ckafka集群,通过Ckafka服务端自带的实例间数据同步能力,实现实例的跨地域间同步复制。这样可以确保当某一个地域不可用时候,消息的读写请求能够正常切换到另一个区。
双集群热备模式说明:
- 服务端内置的Connect集群来实现跨地域间的Ckafka实例集群数据复制。
- 客户端消息读写请求路由到某一地域的主服务实例上,当主服务实例出现异常的时候,客户端的请求将被切换到另外一个地域
的集群上,确保客户端能够继续正常使用。 - 整个数据读写请求不跨区 数据同步复制云上实例可以通过控制台配置同步源&目标端即可实现跨集群间数据同步。
- 通过同步消费offset数据,可以实现切换备区之后继续无缝消费。客户侧无需部署同步组件mirrormaker,并且云上负责对同步
组件的监控维护。可以通过双向同步或者双写来完成数据复制。 故障切换客户侧可以以每个Ckafka实例为单位,通过DNS将
所有流量切换到备区。 - 切换之后可以继续进行消息无缝生产/消费。
Ckafka迁移方案
双写模式:
操作步骤:
- 在腾讯云消息队列 CKafka 控制台,创建 CKafka 实例,并创建对应 Topic。
- 换修改客户侧应用,生产者将数据同时写入到自建kafka及云Ckafka实例。同时启动应用。
- 原有消费者无需做配置,持续消费自建 Kafka 集群的数据。在某一个时间点内,同步启用新的消费者组进行消费,同时停止老的消费者消费。
- 新消费者持续消费 CKafka 集群中的数据,迁移完毕。
同步迁移模式:
同步迁移模式:
- 同步模式操作步骤:在腾讯云消息队列 CKafka 控制台,创建 CKafka 实例,并创建对应 Topic。
- 客户侧生产者继续将数据写入到自建kafka实例。
- 下载、安装并且搭建mirror-maker客户端。
- 配置mirror-maker生产&消费properties文件。
- 启动mirror-maker,开始执行消息数据同步操作。检查数据同步是否正常,如果出现异常,需要检查下相关配置文件。
- 修改kafka客户侧,根据某个时间点启动新的消费。
ES跨可用区容灾
ES的容灾部署模式可以分为:大集群节点跨区部署、跨区复制CCR 2种模式。
大集群节点跨区部署
ES集群包含多个节点,可以将这些节点跨区部署,结合ES主分片&副本分片切换的特性,可以实现当某个主分片挂了情况下,能将副本分片提升为主分片继续对外提供服务。
跨区部署说明:
- ES跨可用区集群:实例采用4个数据节点组成,其中:4区2个,6区2个节点。
- 专用主节点:在每个可用区部署一个专用主节点,从而保障任何一个可用区不可用时,依然能够选出 Master节点,确保整个集群的稳定。
高可用说明:
- VIP实现跨可用区(AZ)访问能力,ES具有故障跨可用区漂移能力。当4区与6区网络出现中断,部署在4区的应用可访问6区ES点。
- 当4、6区任意一个可用区出现故障:如果有一个可用区挂掉,如广州4区整体不可用,ES的Master节点依然可用,会将广州4区的节点剔除并且将广州6区各节点上副本分配提升为主分片,同时VIP会将6区的RS剔除掉,这样4区应用就不会请求到6区节点上了,这样整个集群依然能够对外提供服务,并且对客户侧是无感知的。当故障恢复之后,分片会自动均衡到2个可用区,整个集群自行恢复。
- 当4、6区之间网络抖动、断开之后:通过VIP切换,客户端可正常对ES集群上各节点进行读写。此时因为4区到6区的网络出现抖动等异常情况时: 1)如果Master在4区,Master会将6区节点剔除,留下4区节点,将4区上的副本分片提升为主分片,整体正常对外提供服务。整个过程小于3秒,采用重试规避。 2)如果Master在6区,Master会将4区节点剔除,留下6区节点,将6区上的副本分片提升为主分片,整体正常对外提供服务。整个过程小于3秒,采用重试规避。3. 如果网络恢复正常之后,分片会自动均衡到2个可用区,并且开始执行主分片与副分片数据同步。
CCR 跨区复制模式:
高可用部署说明
- 当四区不可用时,进行容灾切换,业务流量切换到六区1、 断开CCR同步2、 六区切换为普通单实例集群 3、业务手动将所有流量切换到六区(修改DNS等)。
- 当四区恢复后,建立CCR从六区同步数据到四区,六区成为主集群、四区为副集群1、清空四区集群索引2、配置CCR主从同步:数据从六区主集群通过CCR复制到四区副集群。
- 回切四区为主集群1、 断开CCR同步,由于此时数据还继续写入六区,这部分数据会丢失,无法同步到四区2、 四区改为普通单实例集群3、业务手动将所有流量切换到六区,会产生业务中断。
ES大集群部署及CCR跨区复制部署优劣比对
自建ES上云迁移方案
操作步骤
- 腾讯云ES版本需要大于等于客户自建ES集群的版本。
- 例如客户ES版本是6.5.1,则云上的ES版本最好是6.8.2。
- 创建云上ES集群的VPC选择自建集群所在的VPC。
- 腾讯云ES版本选择基础版或者开源版,白金版暂不支持(如果自建ES集群也是白金版可忽略),可在数据迁移完成之后升级到白金版。
- 确保自建ES集群没有开启security,如果开启则先关闭。
- 确保客户自建ES集群没有安装腾讯云ES集群不支持的插件。云上集群的配置名称需要和自建集群保持一致。
Redis跨区容灾方案
Redis容灾主要分为主从和集群。
Redis主从容灾
跨区部署说明
两可用区,1主3副本部署,主可用区1主1副本,备可用区2个副本,每个可用区两个节点,可保障单机故障读请求不跨可用区,单可用区故障后仍然具备主备高可用。该方案适合于对可用性和访问延迟要求较高的场景。
高可用说明:
- VIP实现跨可用区(AZ)访问能力,多 AZ(可用区)的实例只有一个 VIP,这个 VIP 在整个Region 都可以访问,Redis 的 HA(Highly Available)并不会导致 VIP 变化。
- 当4、6区任意一个可用区出现故障:如果有一个可用区redis挂掉,如6区整体不可用,4区依然提供服务,6区的客户端将会通过Proxys集群访问4区的redis。如果4区不可用,那么6区将选举出master节点,4区客户端将通过Proxys访问6区。如果一个可用区内的单机故障,那么就会由没有故障的节点提供服务。这样整个集群依然能够对外提供服务,对客户侧的影响是有限的,客户端做好重试即可。
- 当4、6区之间网络抖动、断开之后:4区为主可用区,访问不受影响,6区默认15秒之后会主动fail ,此时6区的redis将不提 供服务,但是6区的客户端将会在4,6区网络断开10秒后感知到,然后通过第三方可用区网络访问4区的redis,不影响redis使用。2. 如果网络恢复正常之后,重新开始主分片与副分片数据同步,服务自动恢复正常。
Redis迁移方案
Proxy代理切换步骤:
- 整个切换采用Proxy代理模式,客户应用端可以自行控制,确保灵活、快速实现自建redis切换到云上。
- 应用端直连Proxy,然后通过Proxy进行灵活切换,例如由自建迁移到云上,以及当云上迁移失败,可以从云上又切换到自建。
- 自建redis可以通过DTS迁移到云上redis。云上的redis又可以通过redis slaveof 同步数据到线下,需要客户侧自行配置。5月份升级DTS,确保可以从云上迁移数据到自建。