
本文讲解音频检索技术及其广泛的应用场景。以『听曲识歌』为例,技术流程为具对已知歌曲抽取特征并构建特征向量库,而对于待检索的歌曲音频,同样做特征抽取后进行比对和快速匹配。
💡 作者:韩信子@ShowMeAI
📘 深度学习实战系列:https://www.showmeai.tech/tutorials/42
📘 自然语言处理实战系列:https://www.showmeai.tech/tutorials/45
📘 本文地址:https://www.showmeai.tech/article-detail/311
📢 声明:版权所有,转载请联系平台与作者并注明出处
📢 收藏ShowMeAI查看更多精彩内容

音乐是我们日常生活娱乐必不可少的部分,我们会收听电台、欣赏音乐、我们能通过旋律和音色快速分辨歌曲和歌手。
大家都对 QQ 音乐、网易云音乐等 App 中的『听曲识歌』『哼唱识别』功能并不陌生,但是它是怎么样快速从海量歌曲库中找到匹配的这一首的呢?
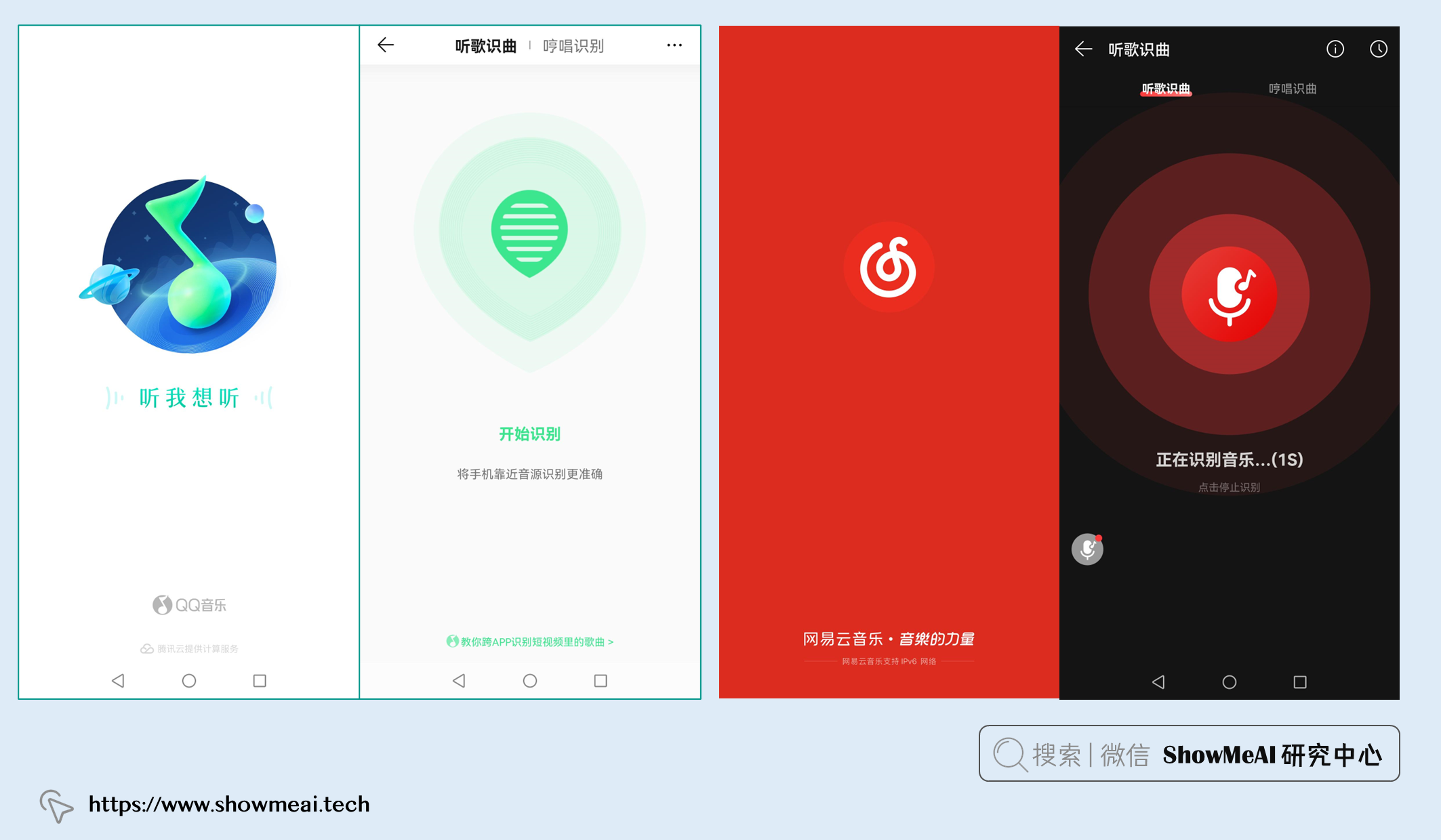
今天 ShowMeAI 就来和大家聊一聊音频检索的技术,实际上音频检索技术有非常广泛的应用场景,除了识歌辨曲,基于实时检索、审查和监控还可以很有效地保护版权。
💡 核心技术
音频检索的核心流程如图所示,我们会对已知歌曲抽取特征并构建特征向量库,而对于待检索的歌曲音频,同样做特征抽取后进行比对和匹配。其中最核心的技术就是『特征提取』和『海量向量数据匹配检索』。
📌 音频特征提取
我们在上述过程里也可以看到,要经过音频内容特征提取后才能进行后续的相似度检索。而特征提取的质量好坏,直接影响最终的效果。有2大类提取音频特征的方法:
- 传统统计模型:经典的高斯混合模型 (GMM) 和隐马尔可夫模型 (HMM) 等。
- 深度学习模型:循环神经网络、长短期记忆 (LSTM)、编码-解码框架和注意力机制模型等。
随着深度学习神经网络技术的不断革新突破,在音频的表征能力上优于传统方法,基于深度学习的音频特征提取技术正逐渐成为音频处理领域的核心技术。
在本篇内容中,特征提取的部分使用的是基于深度学习网络的 📘PANNs (Large-Scale Pretrained Audio Neural Networks for Audio Pattern Recognition) 模型提取音频的特征向量。PANNs 模型的平均准确率 (mAP) 0.439 高于 Google 的0.317。
而提取音频数据的特征向量表征后,我们可以通过 Milvus 实现高性能的特征向量比对检索,关于 Milvus 的介绍可以参考 ShowMeAI 的文章 📘使用Milvus向量数据库进行可扩展的快速相似性搜索。
📌 向量检索引擎
在众多海量数据的场景下进行向量检索,都会采用Milvus这款开源的向量相似度搜索引擎,它具备高效的检索速度和精准的检索精度。
实际上,非结构化的数据,基于深度学习等模型进行特征表征后,都可以借助 Milvus 搭建检索系统,它的整体工作流程如下:
典型的步骤为以下3步:
① 基于深度学习模型,将非结构化数据(图像、视频、语音、文本)转化为表征特征向量。
② 将特征向量存储到 Milvus 并对特征向量构建索引。
③ 对检索数据提取特征并进行向量相似性检索,返回结果。
💡 系统搭建
下面我们搭建基本的音频检索系统,总体包含2个核心板块:
- 音频特征抽取与索引构建(下图黑线所示)。
- 音频数据检索(下图红线所示)。
对应的项目在 Milvus 的官方项目中已开源,地址为 📘Audio Similarity Search,其中使用到的示例数据为开源游戏声音数据。
📌 第一步:特征抽取&索引构建
在 Google drive 中下载示例数据(也可以通过 ShowMeAI 的百度网盘地址下载),
🏆 实战数据集下载(百度网盘):公众号『ShowMeAI研究中心』回复『实战』,或者点击 这里 获取本文 [20]基于深度学习的音频检索技术与系统搭建 『音频检索示例数据集』
⭐ ShowMeAI官方GitHub:https://github.com/ShowMeAI-Hub
遍历文件夹并调用 panns-inference 预训练模型将音频数据转换为特征向量,将得到的特征向量导入到 Milvus 中,Milvus 将返回向量对应的 ID。示例代码如下:
import os
import librosa
import gdown
import zipfile
import numpy as np
from panns_inference import SoundEventDetection, labels, AudioTagging
data_dir = './example_audio'
at = AudioTagging(checkpoint_path=None, device='cpu')
# 下载音频文件
def download_audio_data():
url = 'https://drive.google.com/uc?id=1bKu21JWBfcZBuEuzFEvPoAX6PmRrgnUp'
gdown.download(url)
with zipfile.ZipFile('example_audio.zip', 'r') as zip_ref:
zip_ref.extractall(data_dir)
# 构建音频特征向量并存储
def embed_and_save(path, at):
audio, _ = librosa.core.load(path, sr=32000, mono=True)
audio = audio[None, :]
try:
_, embedding = at.inference(audio)
embedding = embedding/np.linalg.norm(embedding)
embedding = embedding.tolist()[0]
mr = collection.insert([[embedding]])
ids = mr.primary_keys
collection.load()
red.set(str(ids[0]), path)
except Exception as e:
print("failed: " + path + "; error {}".format(e))
# 遍历与操作
print("Starting Insert")
download_audio_data()
for subdir, dirs, files in os.walk(data_dir):
for file in files:
path = os.path.join(subdir, file)
embed_and_save(path, at)
print("Insert Done")📌 第二步:向量检索&音频匹配
在这一步中,我们会继续使用 panns-inference 预训练模型对待检索音频提取特征向量,基于 Milvus 在此前导入 Milvus 库的音频数据特征向量中进行检索。根据检索返回结果并输出。示例代码如下:
# 对待检索音频批量抽取特征,返回embedding
def get_embed(paths, at):
embedding_list = []
for x in paths:
audio, _ = librosa.core.load(x, sr=32000, mono=True)
audio = audio[None, :]
try:
_, embedding = at.inference(audio)
embedding = embedding/np.linalg.norm(embedding)
embedding_list.append(embedding)
except:
print("Embedding Failed: " + x)
return np.array(embedding_list, dtype=np.float32).squeeze()
random_ids = [int(red.randomkey()) for x in range(2)]
search_clips = [x.decode("utf-8") for x in red.mget(random_ids)]
embeddings = get_embed(search_clips, at)
print(embeddings.shape)
import IPython.display as ipd
# 输出结果
def show_results(query, results, distances):
print("Query: ")
ipd.display(ipd.Audio(query))
print("Results: ")
for x in range(len(results)):
print("Distance: " + str(distances[x]))
ipd.display(ipd.Audio(results[x]))
print("-"*50)
embeddings_list = embeddings.tolist()
# 检索参数配置
search_params = {"metric_type": "L2", "params": {"nprobe": 16}}
# 使用milvus进行向量检索并返回结果
try:
start = time.time()
results = collection.search(embeddings_list, anns_field="embedding", param=search_params, limit=3)
end = time.time() - start
print("Search took a total of: ", end)
for x in range(len(results)):
query_file = search_clips[x]
result_files = [red.get(y.id).decode('utf-8') for y in results[x]]
distances = [y.distance for y in results[x]]
show_results(query_file, result_files, distances)
except Exception as e:
print("Failed to search vectors in Milvus: {}".format(e))💡 系统展示
📌 接口展示
完整的音频检索系统基于FastAPI等搭建完成部署,主要接口功能为音频数据插入与删除。启动服务后,在浏览器中输入 127.0.0.1/docs 可查看所有 API。API 查询页面如下图所示:
📌 系统演示
接下来大家就可以上传自己的音频数据,体验基于深度学习与Milvus搜索引擎构建的音频检索系统了,部分系统截图如下:
💡 参考文献
- 📘 PANNs (Large-Scale Pretrained Audio Neural Networks for Audio Pattern Recognition)
- 📘 使用Milvus向量数据库进行可扩展的快速相似性搜索
- 📘 Milvus官网
- 📘 Audio Similarity Search
- 📘 声音检索型业务
- 📘 PANNs: Large-Scale Pretrained Audio Neural Networks for Audio Pattern Recognition
- 📘 Hershey, S., Chaudhuri, S., Ellis, D.P., Gemmeke, J.F., Jansen, A., Moore, R.C., Plakal, M., Platt, D., Saurous, R.A., Seybold, B. and Slaney, M., 2017, March. CNN architectures for large-scale audio classification. In 2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 131-135, 2017