

本文讲解如何使用whylogs工具库,构建详细的AI日志平台,并监控机器学习模型的流程与效果。核心操作包括:环境配置、新建项目并获取ID、获取组织ID和访问Key、将配置文件写入WhyLabs、监控模型性能指标。
💡 作者:韩信子@ShowMeAI
📘 机器学习实战系列:https://www.showmeai.tech/tutorials/41
📘 本文地址:https://www.showmeai.tech/article-detail/395
📢 声明:版权所有,转载请联系平台与作者并注明出处
📢 收藏ShowMeAI查看更多精彩内容
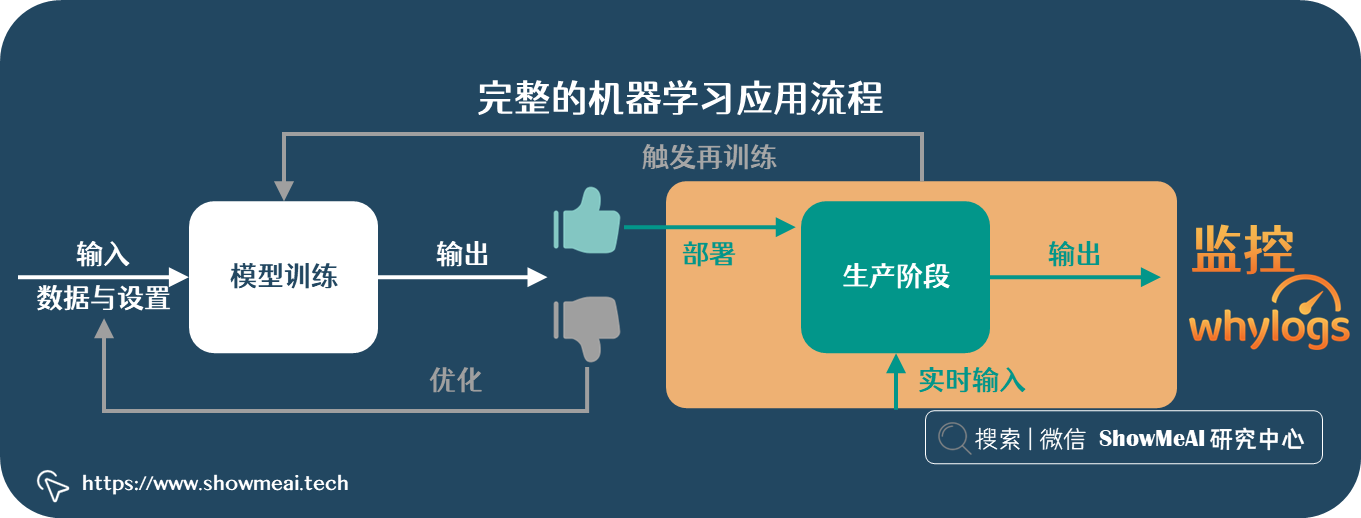
完整的机器学习应用过程,除了数据处理、建模优化及模型部署,也需要进行后续的效果验证跟踪和ML模型监控——它能保证模型和场景是保持匹配且有优异效果的。
模型上线后,可能会存在效果下降等问题,面临数据漂移等问题。详见ShowMeAI的文章 📘机器学习数据漂移问题与解决方案。

ShowMeAI在这篇文章中,将给大家展示如何使用开源工具库 whylogs 构建详尽的 AI 日志平台并监控 ML 模型。


💡 日志系统&模型监控
💦 环境配置
要构建日志系统并进行模型监控,会使用到开源数据日志库📘whylogs,它可以用于捕获数据的关键统计属性。安装方式很简单,执行下列 pip 命令即可
pip install "whylogs[whylabs]"接下来,导入所用的工具库whylogs、pandas和os。我们也创建一份 Dataframe 数据集进行分析。
import whylogs as why
import pandas as pd
import os
# create dataframe with dataset
dataset = pd.read_csv("https://whylabs-public.s3.us-west-2.amazonaws.com/datasets/tour/current.csv")使用 whylogs 创建的数据配置文件可以单独用于数据验证和数据漂移可视化,简单的示例如下:
import whylogs as why
import pandas as pd
#dataframe
df = pd.read_csv("path/to/file.csv")
results = why.log(df)这里也讲解一下云端环境,即把配置文件写入 WhyLabs Observatory 以执行 ML 监控。
为了向 WhyLabs 写入配置文件,我们将 📘创建一个帐户(免费)并获取组织 ID、Key和项目 ID,以将它们设置为项目中的环境变量。
# Set WhyLabs access keys
os.environ["WHYLABS_DEFAULT_ORG_ID"] = 'YOURORGID'
os.environ["WHYLABS_API_KEY"] = 'YOURACCESSTOKEN'
os.environ["WHYLABS_DEFAULT_DATASET_ID"] = 'PROJECTID'💦 新建项目并获取 ID
Create Project > Set up model > Create Project,整个操作过程如下图所示:
💦 获取组织 ID 和访问 Key
菜单 > 设置 > 访问令牌 > 创建访问令牌,如下图所示:
经过这个配置,接下来就可以将数据配置文件写入 WhyLabs。
💦 将配置文件写入 WhyLabs 以进行 ML 监控
设置访问密钥后,可以轻松创建数据集的配置文件并将其写入 WhyLabs。这使我们只需几行代码即可监控输入数据和模型预测!
# initial WhyLabs writer, Create whylogs profile, write profile to WhyLabs
writer = WhyLabsWriter()
profile= why.log(dataset)
writer.write(file=profile.view())我们可以在 pipeline 管道的任何阶段创建配置文件,也就是说可以对每个步骤的数据进行监控。一旦完成将配置文件写入 WhyLabs,就可以检查、比较和监控数据质量和数据漂移。
上述步骤过后,只需单击一下(或创建自定义监视器)即可启用预配置的监视器,检测数据配置文件中的异常情况。设置常见的监控任务是非常容易的,也可以很清晰快捷地检测数据漂移、数据质量问题和模型性能。
配置监视器后,可以在检查输入功能时对其进行预览。
当检测到异常时,可以通过电子邮件、Slack 或 PagerDuty 发送通知。在设置 > 通知和摘要设置中设置通知首选项。
上述这些简单的步骤,我们已经完成了从 ML 管道中的任何步骤提取数据、构建日志和监控分析,并在发生异常时得到通知。
💦 监控模型性能指标
前面看到了如何监控模型输入和输出数据,我们还可以通过在预测结果来监控性能指标,例如准确度、精确度等。
要记录用于监控的性能指标,可以使用why.log_classification_metrics或why.log_regression_metrics并传入包含模型输出结果的 Dataframe。
results = why.log_classification_metrics(
df,
target_column = "ground_truth",
prediction_column = "cls_output",
score_column="prob_output"
)
profile = results.profile()
results.writer("whylabs").write()注意:确保您的项目在设置中配置为分类或回归模型。
在下面的示例笔记本中查看用于性能监控的数据示例。
大家想获得更多关于监控的示例 notebook 笔记本,可以查看官方 GitHub 关于 📘分类和 📘回归的代码。
参考资料
- 📘 机器学习数据漂移问题与解决方案:https://www.showmeai.tech/article-detail/331
- 📘 whylogs:https://github.com/whylabs/whylogs
推荐阅读
- 🌍 数据分析实战系列 :https://www.showmeai.tech/tutorials/40
- 🌍 机器学习数据分析实战系列:https://www.showmeai.tech/tutorials/41
- 🌍 深度学习数据分析实战系列:https://www.showmeai.tech/tutorials/42
- 🌍 TensorFlow数据分析实战系列:https://www.showmeai.tech/tutorials/43
- 🌍 PyTorch数据分析实战系列:https://www.showmeai.tech/tutorials/44
- 🌍 NLP实战数据分析实战系列:https://www.showmeai.tech/tutorials/45
- 🌍 CV实战数据分析实战系列:https://www.showmeai.tech/tutorials/46
- 🌍 AI 面试题库系列:https://www.showmeai.tech/tutorials/48